Insights
The Complex Challenges of Data Syndication

The Importance of Product Information
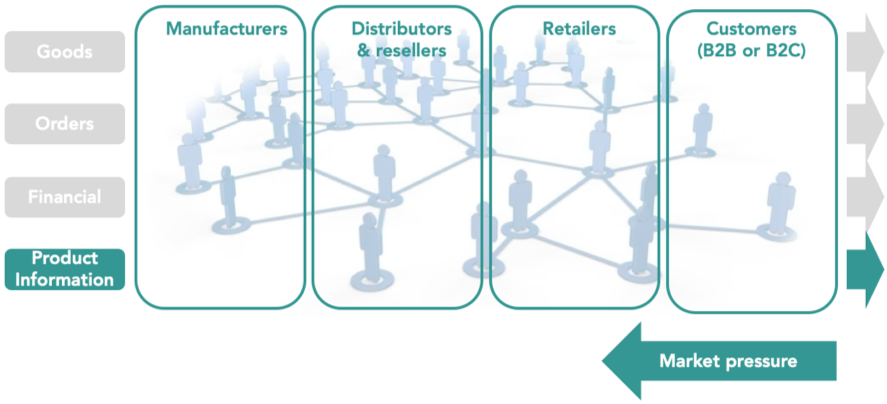
In the past, there was a lot of attention for the physical flow of products and exchange or order and invoice related information between parties in the value chain. Answering questions like: How does a product get from the manufacturer to the distributors’ warehouse? How is the product shipped from the warehouse to the retailer? Or, how can a distributor and retailer optimize their administrative processes by digital exchange of sales and purchase orders? In other words, the focus was on information that falls under Enterprise Resource Planning (ERP), including data on logistics, sales, and order administration. In the overview below, the grey streams represent these activities. This ERP related domain has grown relatively mature over the last decades, however we see that companies are still struggling with e.g. EDI based Order To Cash processes.
On the other hand, there has been lack of attention for the green stream, representing the efficient exchange of structured product data. Especially due to a significant growth in eCommerce and eBusiness, this flow became vital to modern business operations. As customers want to be well-informed about their online purchase, retailers need to provide a lot of product information on the website. Thus, the push for having trusted and rich product information always comes from the right side of the value chain, as shown in the overview below. Retailers do however not have this product data themselves, so they have to ask the distributor or reseller. However, the distributor does not have this product data either, so they have to reach out to the manufacturer.
What is Data Syndication?
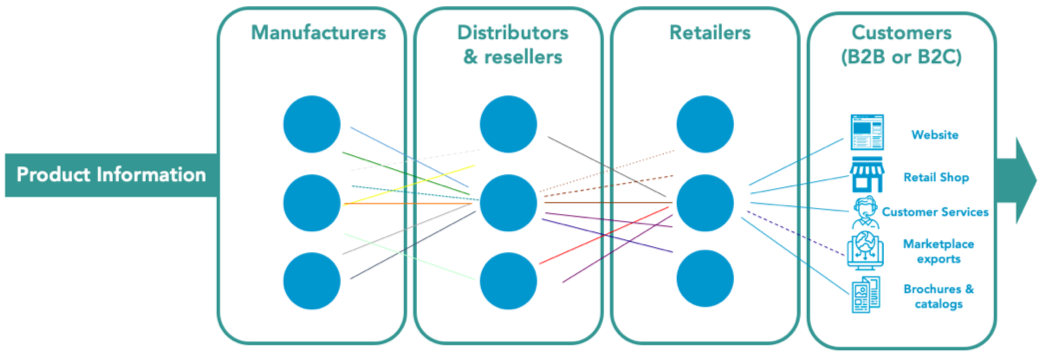
The overview below visualizes the product data challenges for business partners within the value chain. Different organizations collect and store their data in their own way as each of them has their own data model and as such all communicate in their own data-languages. Therefore, efficient Data Syndication is needed. In short, Data Syndication is the synchronization, or syndication, of data between organizations or systems that speak different data-languages. Squadra research confirms this is one of the biggest challenges while implementing Product Information Management (PIM) or Product MDM (Master Data Management).
How Does it Work?
Some organizations try to syndicate data by simply comparing the incoming files with their own datamodel, and ‘translating’ the data by hand. However, imagine having to do this for a retailer selling hundreds or maybe even thousands of different productgroups coming from hundreds of different suppliers, who all have their own data convention. That is simply not intelligent, and incredibly time consuming.
In order to work more efficiently, some organizations work with data pools. Data pools are organizations that gather huge amounts of data, and enable consuming parties, often distributors, wholesalers or retailers, to obtain this data from many suppliers in a uniform format.
Another way for organizations to work more efficiently is to use data standards. As mentioned before, if all organizations speak different languages, and there is a need for some kind of Lingua Franca. Data standards, like GS1, ETIM and ecl@ss, define rules for data records. For example, the GS1 standardization committee decides on the uniform name of the attribute outdoor pillow color and that for outdoor pillow color, the attribute value can only include yellow, blue, or red. By adding these standards, organizations have defined data entry options, creating a common data-language.
How Still to be Unique, Even When Using a Standard?
Imagine having a website selling shoes. In order to help customers find the perfect shoes, many features of a product can be standardized, like the size, material and color of a shoe. However, other information on your website, like marketing texts, should be unique in order to distinguish your organization from your competitors. Jos Schreurs, founding partner of Squadra: “Marketing texts, the product name and preferable metadata of images on the website should be unique, as that is what search engines like Google prefer (SEO). All standard features of a product can be standardized, and additional information like the marketing texts is the unique branding sauce that you pour over your standardized product features in order to be unique”.
The Role of Product Information Management (PIM) Systems
In a PIM system, an organization can manage and organize all relevant product information. PIM systems often have a Vendor Portal and some even include smart datasheets. These are spreadsheets that incorporate supervision on data entering. For example, if in the spreadsheet, the options for color are yellow, blue, and red, and the supplier wants to fill in green, the smart datasheet disallows him to do so. This however does not address the challenge of different data languages as still either one of the parties has to manually transform the data to the right format. “Unfortunately, we see that most PIM vendors use old techniques like business rules and attribute to attribute mapping to transform data. More innovative tooling is however capable of transforming sets of relatively poor data into a uniform data-language using AI and Machine Learning technology. Some PIM tools have recently started to embrace Machine Learning but most often this is still very basic.”
These new technologies are simplifying the challenges of Data Syndication, and Squadra embraced these technologies with the Squadra Machine Learning Company . Due to the lack of the above mentioned functionality, Squadra MLC has developed a set of tools that can be used as add-on on top of a PIM system. This PowerSuite can be used stand-alone (e.g. to create SEO text) as well connected to a PIM system via API’s (e.g. to facilitate machine learning based classification and transformation).
The Role of Squadra Master Data Management
Squadra MDM is a knowledge based and solution driven organization specialized in Product Information Management and Master Data Management. Squadra supports customers in MDM challenges, most oftenincluding Data Syndication. Examples of organizations that Squadra MDM supported with their Data Syndication challenges are Rituals, Kruidvat, De Mandemakers Group, Sonepar (mother Technische Unie) and Wehkamp.
Retailers purchase products from manufacturers for which they need data and they sell them on their website or possibly through other marketplaces, for which they have to provide data. “This sums up the two sides of Data Syndication, gathering and providing data. Data Syndication is in essence reusing data, including the transformation of data in order to reuse it on different platforms, media, or systems” concludes Marc Koetsier, MDM associate at Squadra.
