Insights
How to Automate Product Description Generation Using NLP
In recent years, there has been a growing number of consumers turning to online shopping. For e-commerce businesses, achieving a high ranking on search engines is crucial for drawing potential customers to their websites. Implementing Search Engine Optimization (SEO) is a viable strategy to enhance site visibility. Using identical or replicated product descriptions could negatively affect search engine rankings. Additionally, product descriptions should be informative, realistic, and written in clear language to enhance product visibility.
Natural Language Processing (NLP) methods can expedite the creation of product descriptions. This article utilizes the Transformer model introduced by Vaswani et al. (2017), which we will elaborate on further in the text. We trained this transformer architecture for the Dutch language. The article will explore the potential of automating product description creation, aiming to convert product attributes into accurate, unique descriptions in Dutch. For instance, an input product attribute could be a washing machine’s capacity of 8 kg, with the desired output being a distinct Dutch sentence describing it.
Most existing research has focused on the Chinese language; therefore, we will explain how Dutch descriptions can be generated. Our approach was inspired by the work of Chen et al. (2017), who developed the Knowledge Personalized (KOBE) product description generator utilizing transformer architecture.
Transformer
In 2017, Vaswani et al. fundamentally advanced the field of Natural Language Generation (NLG) with their proposal of a new streamlined network architecture known as the Transformer in their paper titled “Attention is All You Need.” This baseline model surpasses current state-of-the-art BLEU scores across various NLG tasks and requires less training time compared to alternative models. Traditional sequence modeling architectures typically rely on recurrent or convolutional neural networks and employ an attention mechanism to connect the encoder and decoder. In contrast, the Transformer solely utilizes attention mechanisms, featuring a self-attention encoder-decoder structure. Some studies have successfully integrated the transformer architecture into their models, yielding promising results. A visualization of the Transformer architecture is included in the article.
The dataset used consists of approximately 230,000 sentences spanning 52 different product categories, all within the electronics sector. Each product is characterized by specific product attributes, from which we could extract relevant details. However, this dataset’s limitation is significant since it is relatively small for machine learning applications. Although 230,000 sentences may seem substantial, machine learning models typically require larger datasets. Moreover, these descriptions are dispersed across around 50 product categories, with not every sentence containing a product attribute (only 75,000 sentences included at least one attribute). Since we aim to convert attributes into Dutch sentences, we can only utilize a limited number of sentences. To leverage additional data, we employed the Term Frequency Independent Document Frequency (TF-IDF) method to identify the two most unique words in each sentence, defining uniqueness as words that occur infrequently throughout the entire corpus.
The choice of words in the input significantly impacts the output. This blog outlines various approaches and identifies which are effective and which are not. The outputs generated are always single sentences, as attempts to produce longer descriptions have not yet succeeded. During training, the multi-BLEU score was employed as an evaluation metric, commonly used in text generation tasks. Our evaluation primarily focused on the uniqueness of the generated sentences. It was discovered that many sentences were directly lifted from the training set, which is not the intended goal, as we aim to create unique sentences. The uniqueness percentage indicates the proportion of generated sentences that were not directly replicated from the training data.
The highest uniqueness score resulted from using all available data, inputting the product category along with the two TF-IDF words (the most unique words from a sentence). After training, the model achieved a uniqueness score of about 70%. The intention behind this method was to mostly extract product attributes, but ultimately, this approach did not yield optimal results as product attributes were not recognized as unique words. Since we seek to generate descriptions from attributes, this configuration proved inadequate. Nonetheless, the model demonstrated its capacity to create unique sentences.
In the second experiment, we input the product category alongside the product attributes. This limited the available data, as only sentences that described an attribute could be included. In approximately 10% of cases, the model succeeded in generating unique sentences, producing the following examples in Dutch:
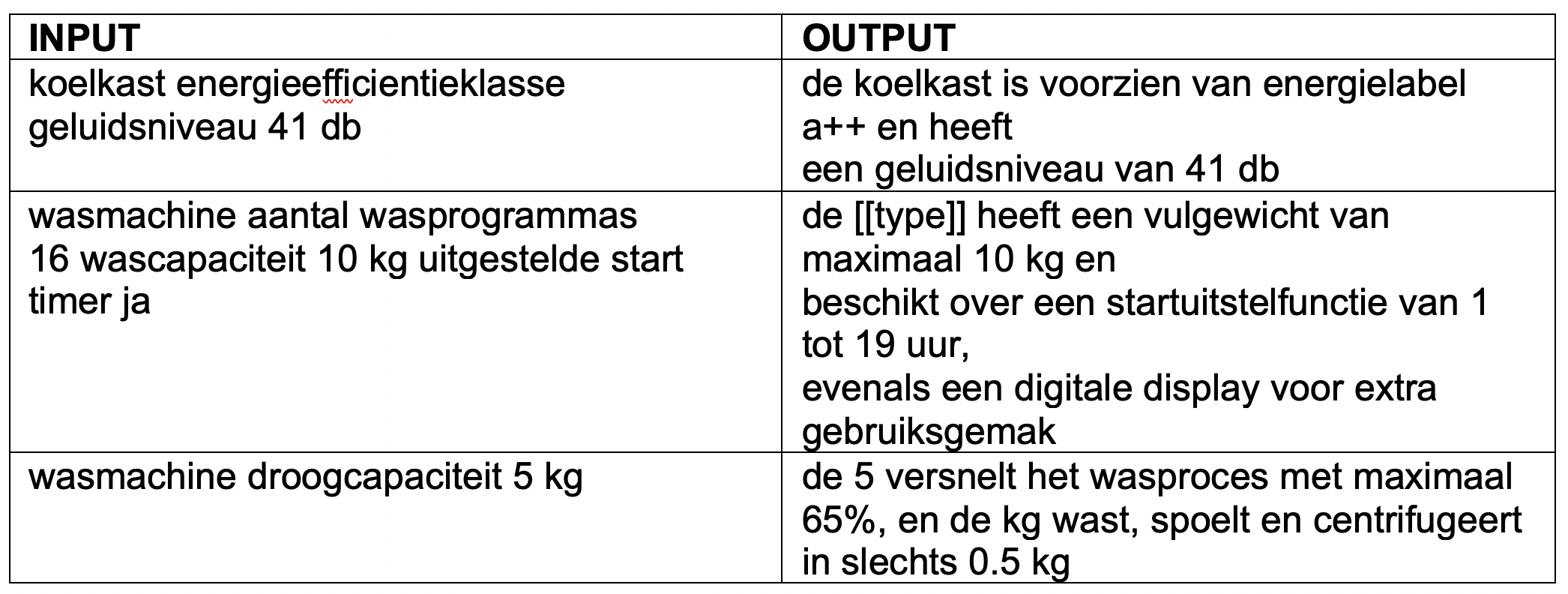
This blog explored the feasibility of generating product descriptions. It was confirmed that this is achievable in Dutch, although further research is necessary to fine-tune the models. A challenge faced is the limited textual data available for the Dutch language, which is crucial for machine learning models. Additionally, it is common for the input attributes to appear verbatim in the output, which is acceptable for most attributes. However, overlapping terms like “height adjustable” and “height 24 cm” may lead to erroneous interpretations. Notably, in 25% of instances, the product category present in the input reappears verbatim in the generated output, similar to existing dataset sentences.
In conclusion, generating Dutch product descriptions using a Transformer architecture is indeed possible. Despite a small proportion of the generated descriptions being unique, the model was able to produce original content. Our primary focus remains on translating product attributes into descriptions, with around 10% of these being unique while accurately reflecting the necessary attributes and being articulated in proper Dutch.
