Insights
Schema Matching voor Productclassificatie

In de afgelopen jaren is het aanbod van verschillende producten in webshops sterk toegenomen. Dit heeft geleid tot de noodzaak voor fabrikanten om productinformatie aan de shop te verstrekken. Als iedere fabrikant dit op zijn eigen manier zou doen, zou dat zorgen voor veel verwarring. Daarom is er een standaardformaat ontwikkeld, zoals het ETIM-formaat, voor diverse elektronische apparaten. Veel fabrikanten hebben hun productinformatie echter nog niet in dit gestandaardiseerde formaat, wat de reden is dat Squadra MLC een conversietool heeft gecreëerd. Een functie van deze tool is om producten in de juiste ETIM-categorie te classificeren, zoals ‘stofzuiger’ of ‘wasmachine’.
Probleemstelling
Aanvankelijk werd de productclassificatie uitgevoerd met een multinomiaal, logistisch regressiemodel. De trainingsdata voor dit model bevat echter niet alle mogelijke ETIM-categorieën. Hierdoor worden producten met ETIM-categorieën die niet in de trainingsdata voorkomen, vaak slecht geclassificeerd. Het doel van dit onderzoek was dan ook een classificatiemodel te ontwikkelen dat in staat is om ook deze minder voorkomende ETIM-categorieën te classificeren.
Geanalyseerde Databestanden
Voor de studie zijn er twee databestanden ter beschikking gesteld: de elektronica-dataset en de ETIM-dataset. De elektronica-dataset bevat producten die nog niet in het ETIM-formaat zijn en dus geclassificeerd moeten worden. Deze dataset omvat onder andere productomschrijvingen en kenmerken. De ETIM-dataset bevat daarentegen de standaardbenamingen en codes voor de ETIM-omschrijvingen en -kenmerken.
Oplossingsstrategie
Schema matching is een mogelijke oplossing voor het eerder genoemde probleem. Bij schema matching worden de gegevens van het te classificeren product vergeleken met die van de mogelijke ETIM-categorieën. De ETIM-categorie met de meeste overeenkomsten zal worden toegewezen aan het product. Figuur 1 toont een voorbeeld waarbij een product dat moet worden gecategoriseerd, wordt vergeleken met een mogelijke ETIM-categorie.
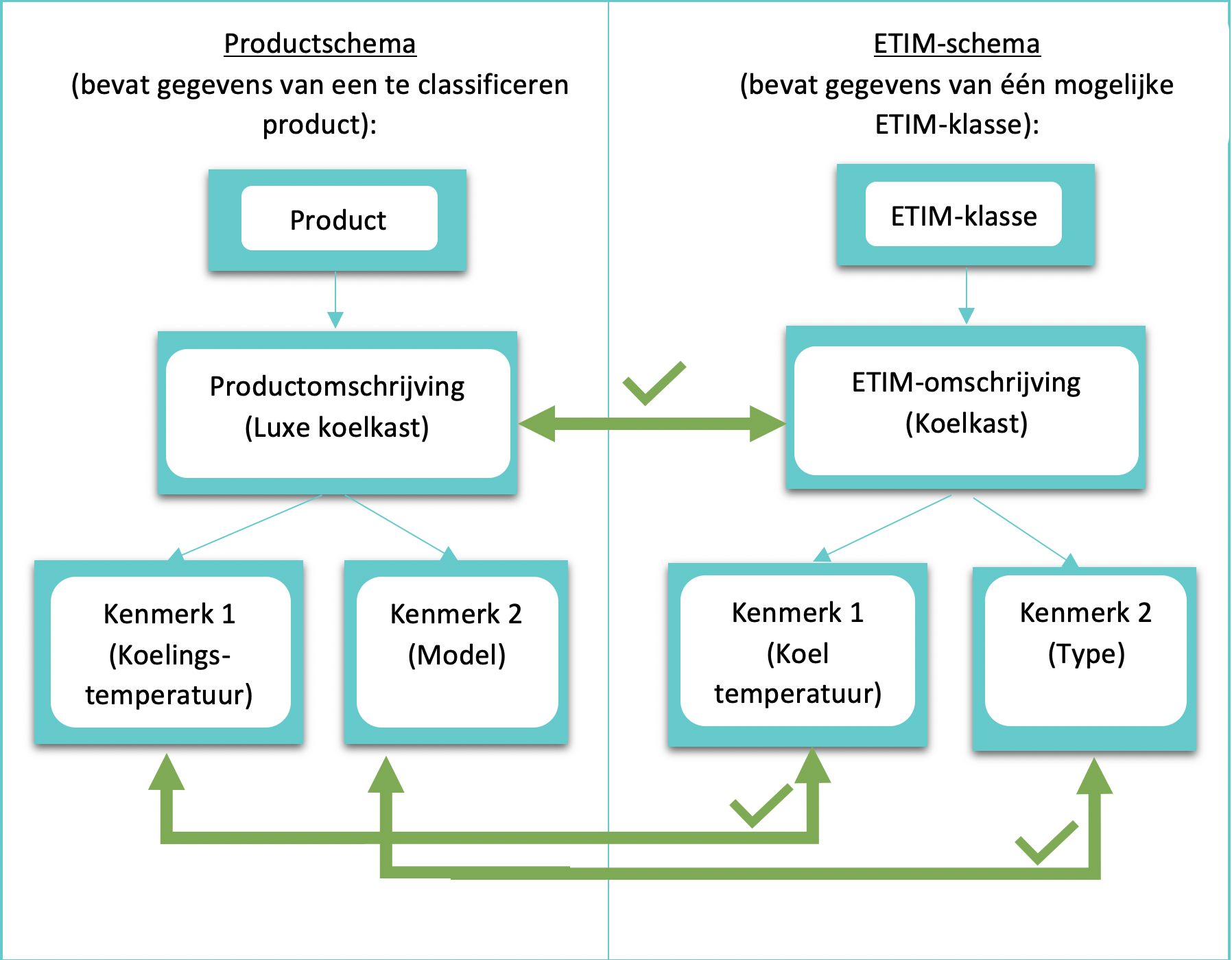
Hybride Naam-matcher
De schema-elementen van het product in figuur 1 worden vergeleken met de schema-elementen van het ETIM-schema met behulp van een hybride naam-matcher. Deze matcher berekent een waarde tussen 0 en 1 die de mate van overeenkomst tussen twee strings (zoals ‘luxe koelkast’ en ‘koelkast’) aangeeft; deze waarde wordt de similarity score genoemd. Een score van 0 betekent geen overeenkomst en een score van 1 betekent dat de elementen identiek zijn. De hybride naam-matcher is gebaseerd op twee componenten:
- De 3-Gram-matcher Deze matcher analyseert het aantal overlappende deelreeksen van drie opeenvolgende karakters en is dus enkel geschikt voor tekstuele overeenkomsten. De 3-Gram-matcher kan bijvoorbeeld de overeenkomst tussen ‘koelkast’ en ‘koelkastje’ detecteren.
- De cosine similarity matcher met vooraf getrainde embeddings Deze embeddings zijn numerieke representaties van woorden. De overeenstemming tussen twee strings wordt vastgesteld door de hoek tussen de embeddings te meten: een kleinere hoek resulteert in een hogere similarity score. Dit type matcher heeft als voordeel dat het ook synoniemen en verwante termen kan herkennen; de gelijkheid tussen ‘toilet’ en ‘wc’ kan bijvoorbeeld wel worden aangetoond door de cosine similarity matcher, maar niet door de 3-Gram-matcher.
Similarity Flooding Algoritme
Het similarity flooding algoritme bepaalt de overeenkomsten tussen schema-elementen door zowel de overeenkomsten in de namen als de structuur van de schema’s in aanmerking te nemen. Dit algoritme is gebaseerd op de veronderstelling dat als twee elementen gelijk zijn, ook hun ouders en kinderen enige mate van overeenstemming vertonen.
De werking van het similarity flooding algoritme kan het beste worden verklaard met behulp van een voorbeelddiagram (zie figuur 2). Dit voorbeeld betreft een product met twee kenmerken dat geclassificeerd moet worden. In dit geval is er keuze tussen twee mogelijke ETIM-categorieën: ETIM-categorie 1 en ETIM-categorie 2.
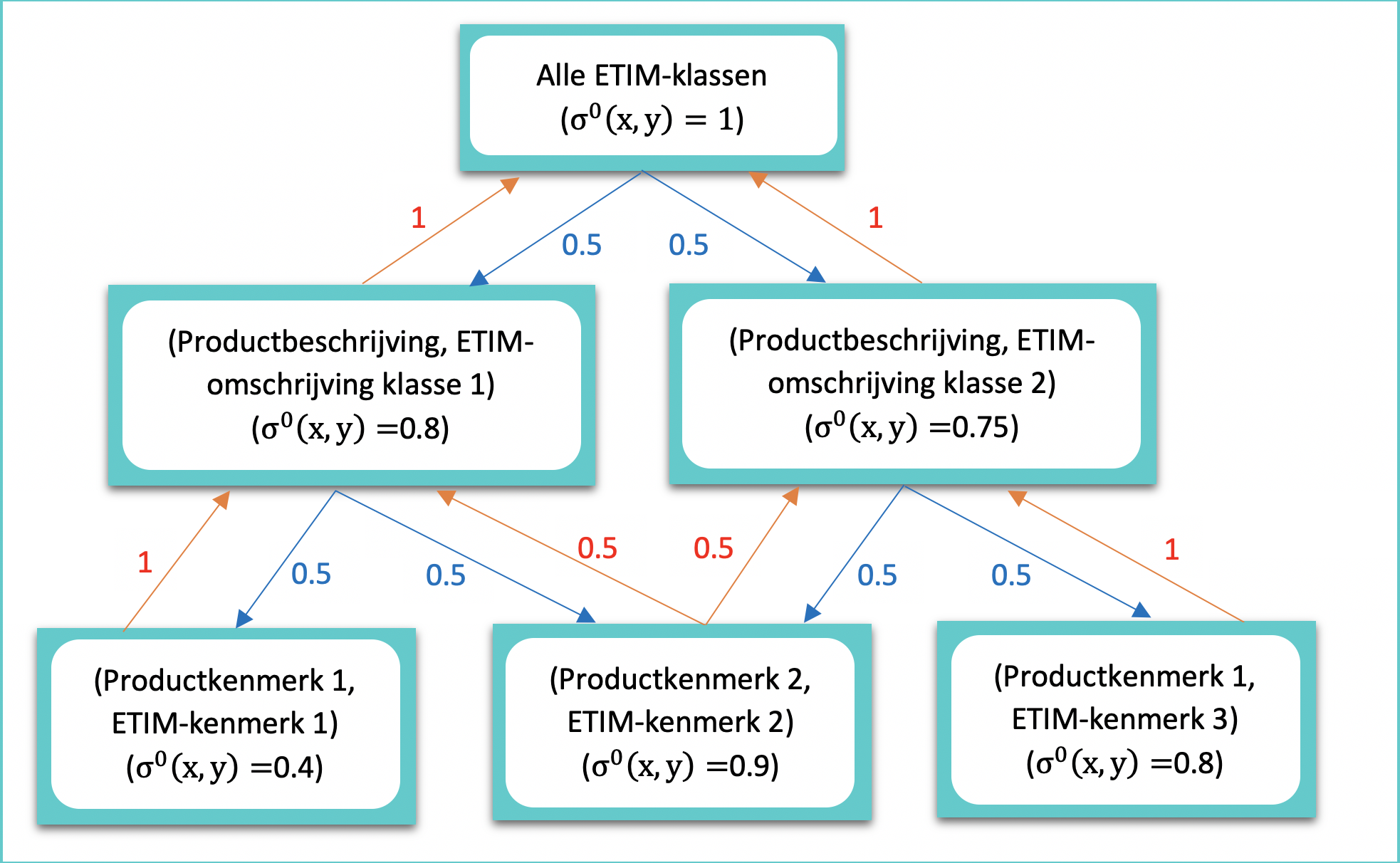
Het voorbeelddiagram bestaat uit drie lagen. De eerste laag bevat het startpunt, een verzameling van alle mogelijke ETIM-categorieën waarin het product kan worden ingedeeld. De similarity score van deze laag wordt op 1 gezet, omdat de overeenkomsten nog onbekend zijn.
In de tweede laag worden de productomschrijvingen vergeleken met de ETIM-omschrijvingen, en in de derde laag worden de productkenmerken vergeleken met de ETIM-kenmerken. De similarity scores in deze twee lagen worden berekend met de hybride naam-matcher.
Vervolgens worden de similarity scores uit figuur 2 (deels) doorgegeven aan hun buren. Dit proces is gebaseerd op de veronderstelling dat wanneer twee elementen identiek zijn, hun ‘ouders’ en ‘kinderen’ (buren) ook enige gelijkheid vertonen. Hierdoor stijgt de similarity score van de productomschrijving met de ETIM-omschrijving van klasse 2, omdat de bijbehorende kenmerken goed op elkaar aansluiten. De gewichten bij de pijlen geven aan hoe goed de similarity score aan de buren wordt doorgegeven.
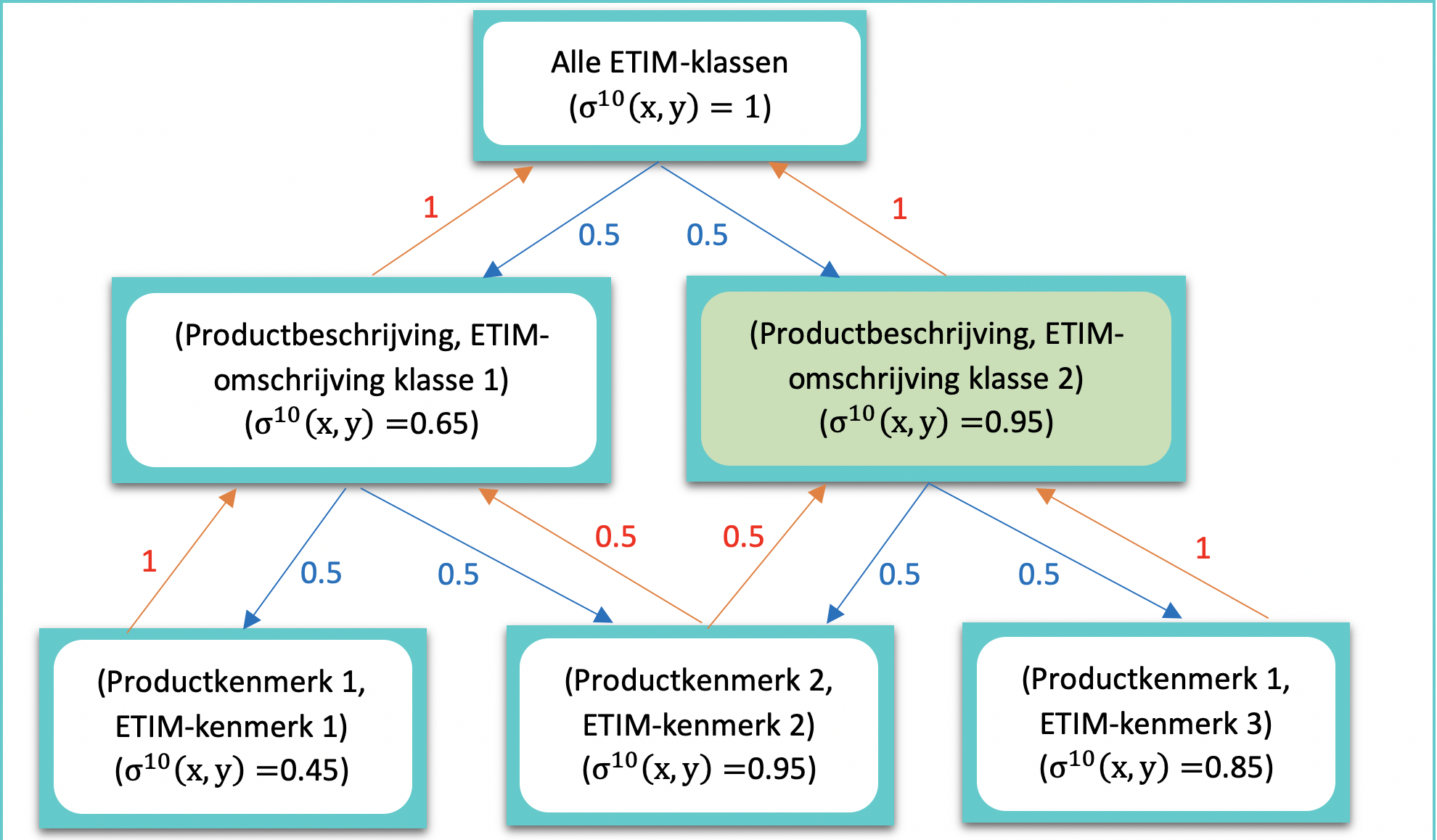
Figuur 3 toont het resultaat na het doorgeven van de similarity scores aan de buren. Om te bepalen in welke ETIM-categorie het product wordt geclassificeerd, wordt gekeken naar de similarity score van de beschrijvingen. Hieruit blijkt dat ETIM-categorie 2 de hoogste score heeft, waardoor het product wordt gecategoriseerd in ETIM-categorie 2.
Conclusie
Het similarity flooding algoritme heeft geleid tot een aanzienlijke verbetering van het classificatiemodel. Een nadeel van dit algoritme is echter dat de resultaten afnemen naarmate er meer producten met vergelijkbare kenmerken zijn, en dat de classificatie tijdrovend is vanwege het grote aantal vergelijkingen.
Referenties
- Melnik, S., Garcia-Molina, H., & Rahm, E. (2002). Similarity flooding: a versatile graph matching algorithm and its application to schema matching. Proceedings 18th International Conference on Data Engineering. doi.org .
