Insights
Schema Matching for Product Classification

In recent years, the number of different products offered by webshops has significantly increased. As a result, multiple manufacturers need to provide product data to these webshops. If everyone were to do this in their own way, it would lead to a lot of confusion. For this reason, a standard format has been introduced for electrical and electronic devices, known as the ETIM format. Many manufacturers have not yet standardized their product data in this format, which is why Squadra MLC offers a conversion tool. One of the tasks of this tool is to classify products into the correct ETIM classes, such as ‘vacuum cleaner’ or ‘washing machine’.
Problem and Objective
Previously, this product classification was done using a multinomial logistic regression model. However, the training data used for this model does not include all possible ETIM classes. As a result, products with ETIM classes not present in the training data are generally not well classified. Therefore, the objective of this research was to develop a classification model that can classify products with ETIM classes not present in the training data.
Datasets Used
For this research, two datasets were provided: the electronics dataset and the ETIM dataset. The electronics dataset contains products that are not in ETIM format and therefore need to be classified into an ETIM class. This dataset includes product descriptions and characteristics. The ETIM dataset contains standard names and codes for ETIM descriptions and characteristics.
Solution Approach
A solution to the mentioned problem is schema matching. Schema matching compares the data of the product to be classified with the data of possible ETIM classes. The ETIM class with the most similarities is the class in which the product is classified. Figure 1 illustrates an example where a product to be classified is compared with one possible ETIM class.
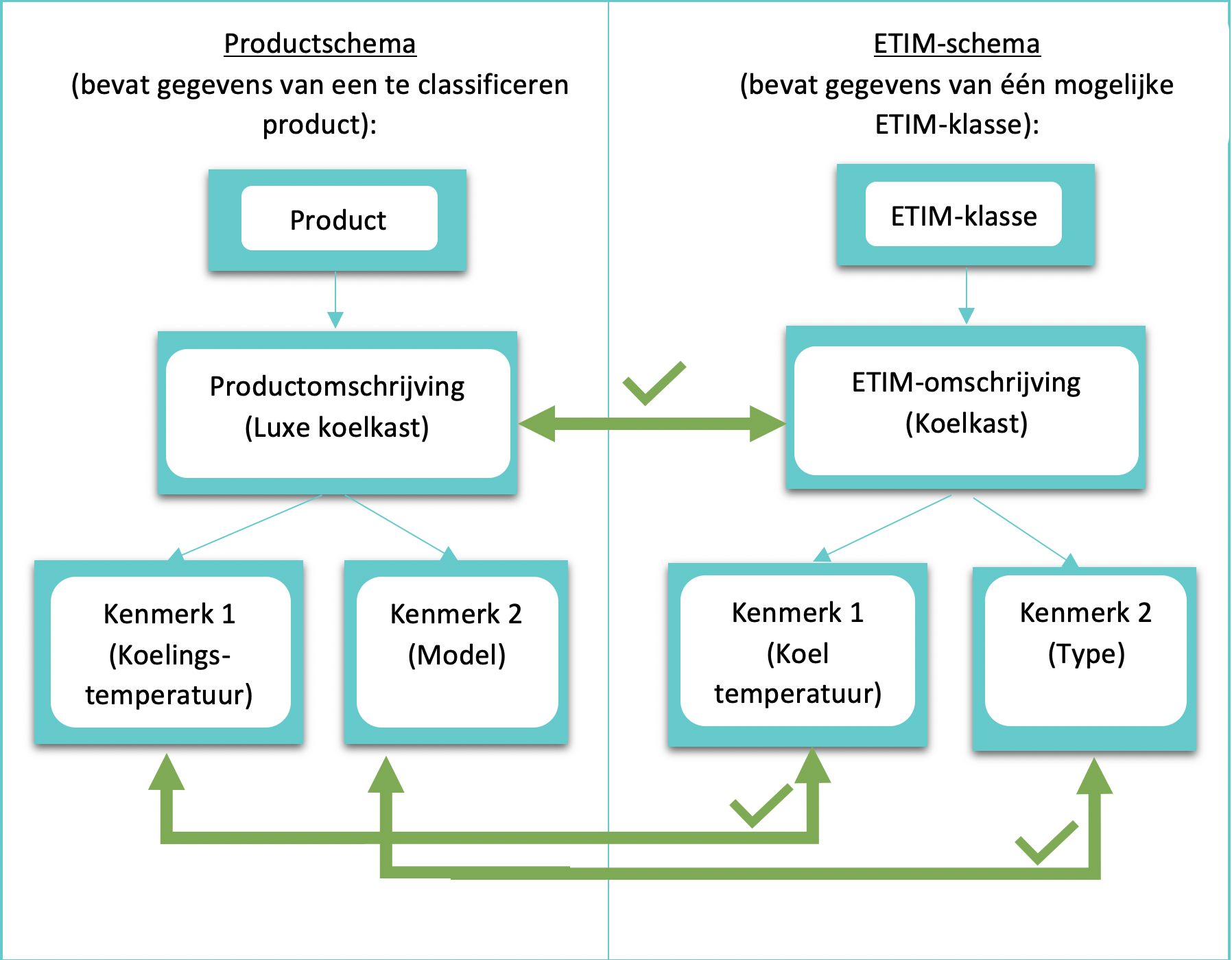
Hybrid Name Matcher
The schema elements of the product schema from figure 1 are compared with the schema elements of the ETIM schema from figure 1 using a hybrid name matcher. This matcher calculates a value between 0 and 1 indicating the degree of similarity between two strings (e.g., ’luxury refrigerator’ and ‘refrigerator’); this value is referred to as the similarity score. A similarity score of 0 implies no similarity, while a score of 1 implies exact similarity between the elements. The hybrid name matcher used is based on two matchers:
- 3-Gram Matcher: This matcher examines the number of matching subsequences of three consecutive characters and compares based solely on text. For instance, the similarity between ‘refrigerator’ and ‘mini refrigerator’ can be recognized by the 3-Gram matcher.
- Cosine Similarity Matcher with Pretrained Embeddings: Pretrained embeddings are numeric vectors representing words. The similarity between two strings is determined by the angle between these embeddings: smaller angle indicates higher similarity score. This matcher can recognize synonyms and relationships. For example, the similarity between ’toilet’ and ‘WC’ can be recognized by the cosine similarity matcher but not by the 3-Gram matcher.
Similarity Flooding Algorithm
The similarity flooding algorithm identifies similarities between schema elements by considering both the similarity in element names and the structure of the schemas. The algorithm operates on the premise that if two elements are similar, their parents and children are also somewhat comparable.
The overall functioning of the similarity flooding algorithm is best explained through an example diagram (see figure 2). The example involves a product with two characteristics that need classification. In this scenario, a choice can be made between two possible ETIM classes: ETIM class 1 and ETIM class 2.
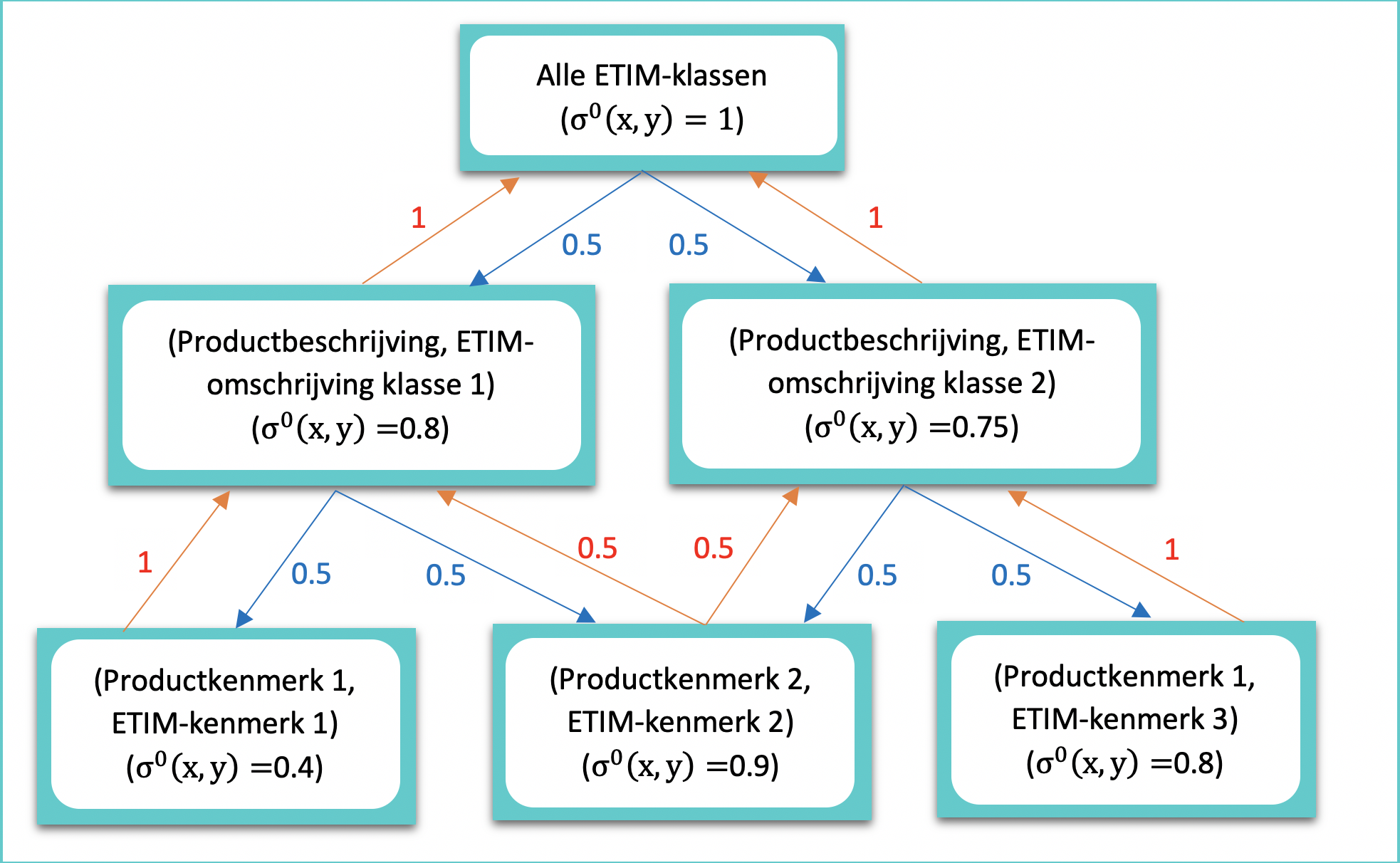
The example diagram can be divided into three layers. The first layer of the diagram consists of the starting point, which is a collection of all possible ETIM classes in which a product can be classified. The similarity score of this layer is set to 1 because the similarities are unknown.
In the second layer, the product description is compared with the possible ETIM descriptions, and in the third layer, the product features are compared with the ETIM features. The similarity scores in these two layers are calculated using the hybrid name matcher.
Subsequently, the similarity scores from figure 2 are partially passed on to their neighbors. This is based on the premise that if two elements are the same, their “parents” and “children” (neighbors) are somewhat similar too. As a result, the similarity score of the product description with the ETIM description of class 2 increases, because their associated features match well. The weights on the arrows determine how effectively the similarity score is passed on to its neighbors.
Figure 3 represents the result after passing on the similarity scores to their neighbors. To determine in which ETIM class the product will be classified, we look at the similarity score of the descriptions. It turns out that ETIM class 2 has the highest similarity score, so the product will be classified in ETIM class 2.
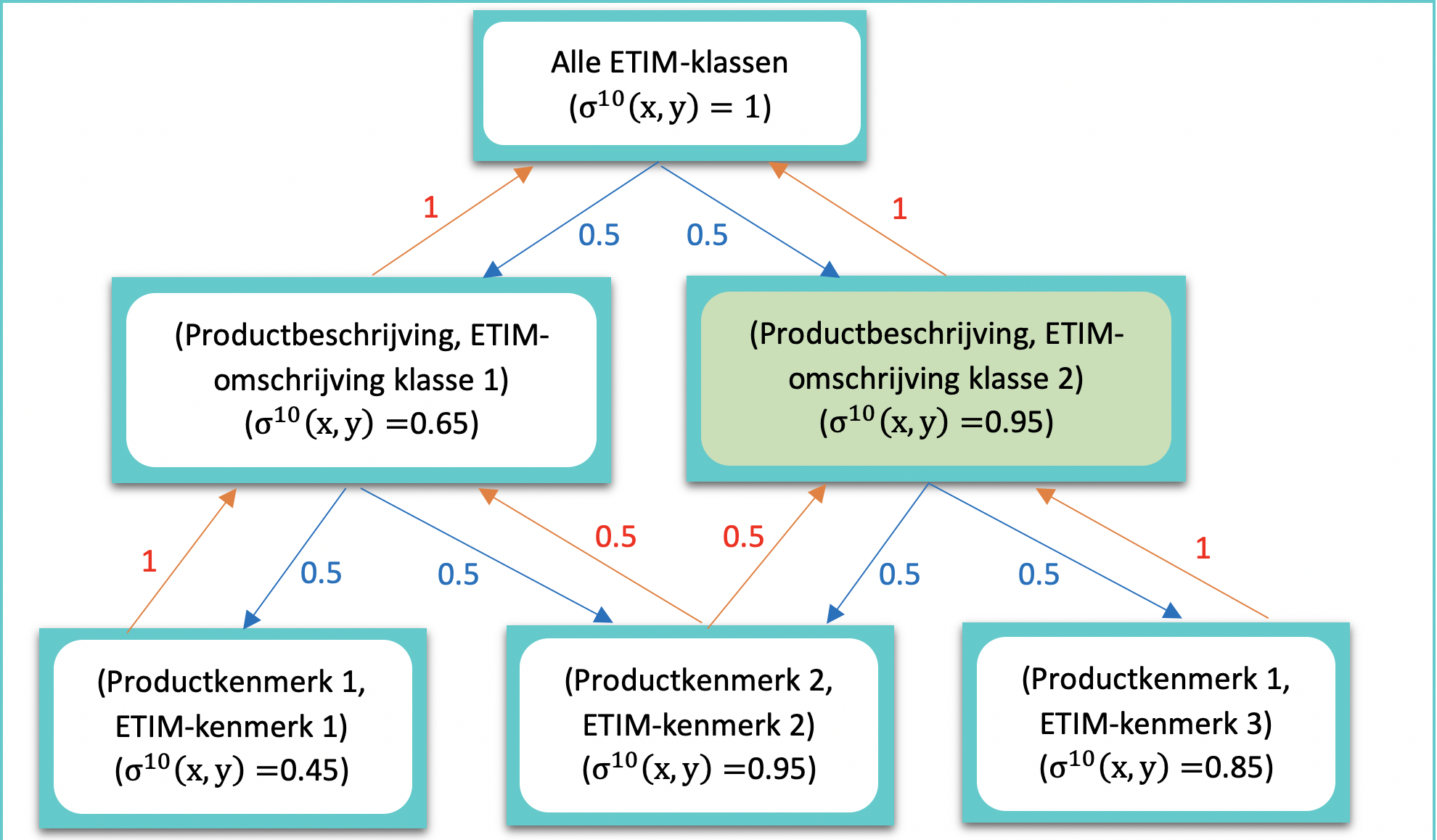
Conclusion
The similarity flooding algorithm has led to a significant improvement in the classification model. However, a drawback of this algorithm is that the results deteriorate as more products with similar characteristics are involved, and the classification process takes longer due to the large number of comparisons.
References
- Melnik, S., Garcia-Molina, H., & Rahm, E. (2002). Similarity flooding: a versatile graph matching algorithm and its application to schema matching. Proceedings 18th International Conference on Data Engineering. doi.org .
