Insights
Crafting a Paraphrasing Recipe Using T5

Transformer-based models have quickly become the leading technology for many tasks in Natural Language Processing (NLP), with OpenAI’s GPT-3 being one of the most well-known examples. These models can assist individuals with various writing duties and reduce the labor-intensive aspects of the process.
Consider a retailer selling multiple variations of a particular product type. To attract customers on your website, you need unique product descriptions, and for SEO reasons, it’s essential to avoid using the same description across all similar products. While creatively writing an engaging product description is enjoyable, generating 10 slightly modified versions can be tedious. In this blog, we’ll demonstrate how to train a model to automatically produce paraphrases from an input sentence.
If you’re exploring this article due to an interest in NLP, you’ve likely encountered the transformer by now. If not, here’s a brief update. The transformer is a neural network architecture highly effective for sequence modeling[^1]. It features an encoder-decoder design, eliminating the commonly used recurrent and convolutional structures and relying entirely on self-attention mechanisms. This self-attention enables the model to process the entire input sequence simultaneously, granting it a much larger long-term memory than other neural frameworks.
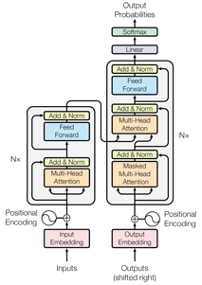
Using this transformer framework, numerous multi-functional language models have been developed to excel in various natural language processing and generation tasks. Think of the original transformer architecture as pasta dough, with subsequent models representing the different pasta shapes formed from it for their specific purposes. Just as pasta shape affects the choice of sauce, different transformer-based models are suited for different NLP tasks. For instance, Google’s BERT, composed solely of encoder blocks from the original transformer, excels at tasks like question-answering, while models from the GPT series, based only on the decoder component, shine in natural language generation.
When selecting our pasta shape, we must consider our paraphrasing sauce. A pair of paraphrases consists of two sentences that convey the same idea but employ different wording. In our case, this means altering an input sentence into a new sentence while preserving the original meaning. This task differs from question-answering or natural language generation, necessitating a different type of model. Given that we are transforming one text into another, a model with an encoder-decoder structure is most suitable, leading us to choose T5 for our paraphrasing application.
T5
Google’s Text-to-Text Transfer Transformer, or T5, retains an encoder-decoder structure similar to the original transformer and has been pre-trained on 750 GB of diverse text data[^2]. The model is available in multiple sizes, and for this article, we are fine-tuning the smallest pre-trained version, which has 60 million parameters, using the Huggingface Transformers library.
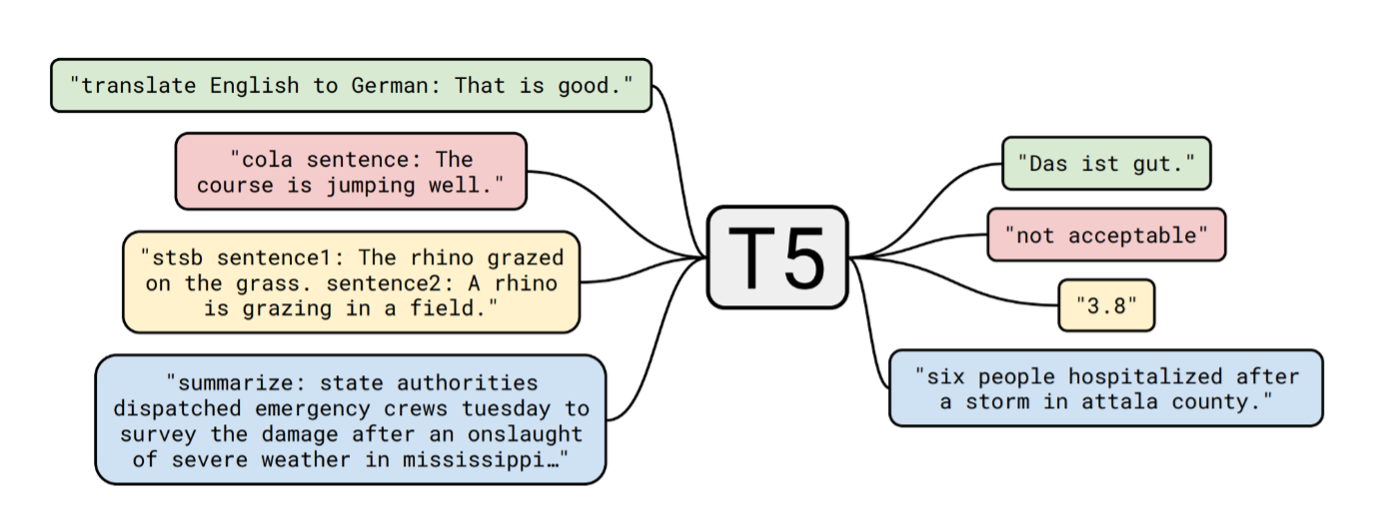
To generalize a model for multiple objectives, T5 approaches every downstream NLP task as a text-to-text problem. For training, T5 requires that each example include both an input and a target. During pre-training, inputs are corrupted by masking sequences of words, which the model then predicts as the target. In fine-tuning, the input remains unchanged while the target reflects the desired outcome.
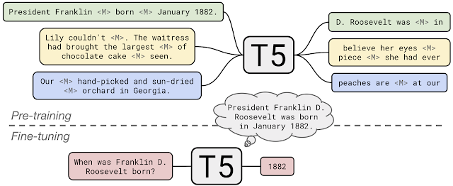
To enable the model to handle different tasks, a prefix is attached to the input during the fine-tuning phase to indicate the specific task corresponding to that input. For our purpose, input and output will consist of paraphrase pairs, so we prepend “paraphrase:” to each input. Once fine-tuned, the model will recognize these prefixes and perform the appropriate task, returning a paraphrase when the input begins with “paraphrase” rather than a translation.
Data
Let’s gather our ingredients for the sauce. To ensure our model learns effectively, we are combining three publicly available datasets containing English paraphrase pairs:
- The Paraphrase Adversaries from Word Scrambling dataset derived from Wikipedia content (PAWS-Wiki)
- The Microsoft Research Paraphrase Corpus (MSRP)
- The Quora Question Pairs dataset
The entries in these datasets were initially labeled as paraphrased or not, allowing us to filter out the non-paraphrased pairs for our needs. This results in a total of 146,663 paraphrase pairs. However, since the Quora Question Pairs dataset is four times the size of the combined PAWS-Wiki and MSRP datasets, training on this large set of questions might lead to generating primarily question outputs. To prevent this, we aim to create a balanced dataset with an equal number of questions and non-questions. The final dataset comprises 65,608 paraphrase pairs, divided into training, testing, and validation sets, with distributions of 0.8, 0.1, and 0.1, respectively.
Output Filtering
As previously mentioned, paraphrasing involves transforming one sentence into another while retaining its meaning. This introduces two constraints for the results. First, the input and output should be semantically similar. Second, there should be sufficient variation in wording. Identical sentences are clearly semantically close but do not paraphrase each other. However, altering every word in a sentence can sometimes change its meaning or nuance. Balancing these constraints is akin to seasoning—a proper mix leads to a tastier result.
To evaluate the semantic similarity between the input and generated outputs, we utilize Google’s Universal Sentence Encoder (USE) to create embeddings for each sentence. These embeddings are 512-dimensional vectors designed so that related sentences cluster closer together in the vector space than unrelated ones. Thus, we can calculate the cosine similarity between the input and output vectors to quantify their semantic proximity, yielding values between 0 and 1, where a higher value indicates greater similarity.
To measure differences in the surface forms, we employ two metrics. ROUGE-L assesses the longest common subsequence of words between input and output, while BLEU reflects n-gram precision at the word level. In both metrics, identical sentences receive a score of 1, while completely dissimilar sentences yield a score of 0. To ensure the outputs are sufficiently distinct from the input, we set a maximum threshold for these scores, discarding any sentences that exceed a ROUGE-L or BLEU score of 0.7. However, these cut-off values can be adjusted as needed.
After filtering the results, we rank the remaining outputs based on their USE scores, selecting the one with the highest score as the best paraphrase.
Results
With our cooking complete, it’s time to sample the results! For each input, we allowed the model to generate 10 potential paraphrases. We then filtered and ranked these based on their USE, ROUGE-L, and BLEU scores. The sentence that ranks highest is our selected paraphrase. Below are examples of paraphrases produced by our model.
| # | Input | Output | USE | R-L | BLEU |
|---|---|---|---|---|---|
| 1 | Having won the 2001 NRL Premiership, the Knights traveled to England to play the 2002 World Club Challenge against Super League champions, the Bradford Bulls. | The Knights came to England for the World Club Challenge 2002 against the Bradford Bulls, the Super League champions after winning the 2001 NRL Premiership. | 0.9611 | 0.4651 | 0.2411 |
| 2 | Is tap water in Italy good for drinking? | Is tap water good for drinking in Italy? | 0.9641 | 0.6250 | 0.3083 |
| 3 | Make sure you have the right gear when you explore the nature. | When exploring nature, make sure you have the right gear. | 0.8350 | 0.5999 | 0.3887 |
These outcomes look promising. Examples 2 and 3 illustrate paraphrasing by rearranging the word order in the input, as reflected in their relatively high ROUGE-L and BLEU scores. Example 1 showcases an excellent balance between the elements, with a completely altered sentence structure yet extremely high semantic similarity. Our paraphrasing model is a recipe for success!
References
[^1]: A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser en I. Polosukhin, „Attention Is All You Need,” Advances in neural information processing systems, pp. 5998-6008, 2017. [^2]: C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Metana, Y. Zhou, W. Li en P. Liu, „Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,” Journal of Machine Learning Research, vol. 21, nr. 140, pp. 1-67, 2020.
