Insights
Transformer-gebaseerde Taalmodellen voor Grootschalige Verrijking van Productgegevens in E-commerce

De manier waarop consumenten en bedrijven inkopen doen, is de afgelopen jaren drastisch veranderd. Aankopen worden steeds vaker online gedaan. De wereldwijde verkoop van e-commerce in de detailhandel wordt voor dit jaar (2022) geschat op 5,55 biljoen dollar, wat goed is voor 21,0% van de totale detailhandelsuitgaven en naar verwachting gestaag zal toenemen. Om aan deze vraag te voldoen, moeten bedrijfseigenaren zich op e-commerce storten of hun bestaande online productportfolio uitbreiden. Een belangrijke voorwaarde voor dergelijke strategieën is de digitale beschikbaarheid van productinformatie. Via de online kanalen moeten consumenten kunnen vinden wat ze zoeken en door deze productinformatie overtuigd worden om tot aankoop over te gaan. Deze gegevens worden meestal opgeslagen in productinformatiebeheersystemen die de e-commerce winkel- en catalogussystemen voeden. In de praktijk zijn veel van de vereiste gegevens echter niet of slechts gedeeltelijk beschikbaar en kunnen ze alleen worden verkregen na intensieve handmatige handelingen. Als gevolg hiervan is bij veel organisaties een groep data stewards fulltime bezig met het verzamelen van de juiste productgegevens uit verschillende bronnen, wat kostbaar, vervelend en inefficiënt is.
Vanuit holistisch oogpunt is het internet misschien wel de grootste bestaande productdatabase die beschikbaar is. Er zijn talloze online winkels die een enorm aantal producten aanbieden op het internet. Gewoonlijk heeft elk product zijn eigen specifieke productdetailpagina (PDP) die de relevante informatie van dat product presenteert. Dit omvat, maar is niet beperkt tot, productafbeeldingen, specificaties, prijs, verzending en beschrijving. Deze informatie ondersteunt consumenten bij hun besluitvorming en is om die reden openbaar beschikbaar. Hierdoor hebben ondernemers die e-commerce willen gaan bedrijven eigenlijk al veel productinformatie tot hun beschikking. De kans is groot dat de producten die deze ondernemers willen aanbieden al op internet worden aangeboden door andere ondernemers die over de juiste productinformatie beschikken. De uitdaging hier is om deze productinformatie automatisch te vinden, op te halen en op te slaan en vervolgens te gebruiken voor het verrijkingsproces. Hiervoor moeten we uitzoeken hoe we wijs kunnen worden uit de enorme, diverse en slecht gestructureerde database waarin deze gegevens zijn opgeslagen. Met andere woorden, hoe kunnen we de uitdagingen van het internet overwinnen voor grootschalige geautomatiseerde verrijking van e-commerce productgegevens. We definiëren hiervoor twee belangrijke uitdagingen: de heterogeniteit in structuur tussen productdetailpagina’s en de syntactische discrepantie tussen beschrijvingen van identieke productspecificaties.
Het eerste probleem is de heterogeniteit in structuur tussen de PDP’s van verschillende online winkels. Zoals gezegd leveren de PDP’s de productgegevens die gebruikt kunnen worden voor het verrijkingsproces. De manier waarop deze gegevens op de PDP’s worden gepresenteerd en gestructureerd, verschilt echter tussen webwinkels. Webwinkels zijn niet verplicht om hun productinformatie in een bepaald formaat te presenteren. Als gevolg hiervan kan de productinformatie in verschillende structuren zijn opgenomen en op verschillende posities op de PDP’s worden weergegeven. Het tweede probleem is de syntactische discrepantie tussen beschrijvingen van identieke productspecificaties. Online winkels maken waarschijnlijk gebruik van hun eigen attribuutnamen en standaardwaarden om hun producten te beschrijven. Er zullen talloze gelijksoortige maar verschillend benoemde attributen zijn met inconsistente waarden door het gebruik van synoniemen, afkortingen, spelfouten, enzovoort. Voor grootschalige gegevensverrijking moeten we duplicaten herkennen en de productspecificaties standaardiseren om gegevens van hoge kwaliteit te garanderen.
In dit artikel zullen we laten zien hoe op transformatoren gebaseerde taalmodellen kunnen worden gebruikt om beide uitdagingen te overwinnen. Eerst zullen we de op transformatoren gebaseerde taalmodellen kort uitleggen. Vervolgens zullen we uitleggen hoe we dergelijke taalmodellen kunnen gebruiken voor het detecteren van productspecificaties op PDP zonder rekening te houden met hun structuur. Tot slot zullen we uitleggen hoe deze taalmodellen kunnen worden gebruikt om productspecificaties te matchen.
Op Transformatoren Gebaseerde Taalmodellen
Het eerste op transformatoren gebaseerde taalmodel werd geïntroduceerd door Devlin et al. (2018). Ze noemden het BERT, Bidirectional Encoder Representations from Transformers. BERT heeft het NLP-landschap aanzienlijk veranderd. In tegenstelling tot eerdere contextuele taalmodellen zoals ELMo, kan BERT rekening houden met alle woorden van een zin tegelijkertijd om de embeddings van de woorden te bepalen. Hierdoor heeft BERT een dieper begrip van taal. Sinds de introductie van BERT zijn er talloze verfijnde en afgeleide versies van BERT verschenen waarvan is aangetoond dat ze beter presteren dan vanille BERT. Al deze taalmodellen zijn gebruikt voor een breed scala aan NLP taken, waaronder semantische tekstuele gelijkenis die we zullen gebruiken om ons probleem op te lossen.
Productspecificaties Detecteren
We noemden het probleem van de heterogeniteit in structuur tussen PDP’s van verschillende online winkels. Productspecificaties kunnen overal op de PDP worden gepresenteerd. Over het algemeen staan ze echter in HTML-tabellen op webpagina’s. Deze productspecificaties beschrijven eigenschappen van het product en zijn daarom gerelateerd aan het product en de productcategorie. Andere HTML-tabellen die op PDP’s worden gebruikt, bevatten meestal de contactgegevens van de winkel, hun openingstijden, hun links naar sociale media en andere informatie die niets met het product te maken heeft. Dit geeft aan dat over het algemeen de productspecificatietabellen de enige HTML-tabellen op de PDP’s zijn die betrekking hebben op het product. Daarom kunnen we ons detectieprobleem formuleren als een semantische zoektaak: we willen alleen de tabellen die betrekking hebben op het product (specificaties) zoeken en ophalen. Semantisch zoeken lijkt sterk op zinsgelijkenis en semantische tekstuele gelijkenis. In essentie worden verschillende zinnen vergeleken door hun semantische gelijkenis te berekenen. Een hoge semantische gelijkenis geeft aan dat twee zinnen dezelfde betekenis hebben of verwant zijn.
We kunnen elke HTML-tabel op een PDP eenvoudig converteren naar een enkele zin door alle woorden in de tabel aan elkaar te rijgen. Dit resulteert in een aantal afzonderlijke zinnen die kunnen worden vergeleken met een bepaalde invoerzin. Zie bijvoorbeeld de conversie van een productspecificatietabel naar een enkele zin hieronder:
| Category | Value |
|---|---|
| Printing Technology | Inkjet |
| Brand | HP |
| Connectivity Technology | Wi-Fi;Cloud Printing |
| Model Name | J9V92A#B1H |
| Compatible Devices | Smartphones, PC, Tablets |
| Recommended Uses For Product | Office, Home |
| Sheet Size | 3 x 5 to 8.5 x 14, Letter, Legal, Envelope |
| Color | Seagrass |
| Printer Output | Color |
| Item Weight | 5.13 pounds |
| Product Line | HP DeskJet |
“Printtechnologie Inkjet Merk HP Connectiviteitstechnologie Wi-Fi;Cloud Printing Modelnaam J9V92A#B1H Compatibele apparaten Smartphones, PC, Tablets Aanbevolen Gebruik Voor Product Kantoor, Thuis Velformaat 3 x 5 tot 8,5 x 14, Letter, Legal, Envelop Kleur Zeegras Printeruitvoer Item Gewicht 5,13 pond Productlijn HP DeskJet”
En ook het omzetten van een HTML-tabel zonder specificatie in een enkele zin (Amazon presenteert sommige categorieën in een HTML-tabel in de voettekst van de pagina):

“Amazon Music Stream miljoenen nummers Amazon Advertising Klanten vinden, aantrekken en binden Amazon Drive Cloudopslag van Amazon 6pm Scoor deals op modemerken AbeBooks Boeken, kunst & verzamelobjecten Verkopen op Amazon Start een verkoopaccount Amazon Business Alles voor uw bedrijf AmazonGlobal Verzend bestellingen internationaal Home…”
We kunnen dit doen voor elke HTML-tabel op het PDP en dan krijgen we n zinnen waarbij n gelijk is aan het aantal HTML-tabellen op het PDP. Maar hoe vinden we de zin(nen) die betrekking hebben op productspecificaties? Hiervoor moeten we een inputzin maken die semantisch gerelateerd is aan de zin die de productspecificaties bevat. Productspecificaties kunnen heel domeinspecifiek zijn, maar zijn op de een of andere manier gerelateerd aan het product en zijn categorie. Neem bijvoorbeeld de specificatietabel hierboven. Deze tabel is opgehaald bij Amazon en bevat enkele specificaties van een specifieke printer. Als gevolg daarvan zien we attributen en waarden gerelateerd aan de printer, zoals ‘printtechnologie’, ‘cloud printing’, ‘kantoor’, ‘velformaat’, ’letter’, ‘printeruitvoer’, enzovoort. Deze zijn duidelijk gerelateerd aan de productcategorie ‘printer’. Dit betekent dat een zin die de productcategorie bevat semantisch gerelateerd kan zijn aan de productspecificaties en daarom gebruikt kan worden voor automatisch semantisch zoeken. Gewoonlijk is de productcategorie opgenomen in de ‘broodkruimels’ van PDP’s, ook bekend als de navigatieketen. We kunnen de broodkruimels dus gebruiken om de productspecificaties te vinden. Voor dezelfde printer van Amazon zien we de volgende broodkruimels die ook kunnen worden omgezet in een enkele zin:
“Kantoorproducten ’ Kantoorelektronica ’ Printers & accessoires ’ Printers”
Nu de breadcrumbs en HTML-tabellen zijn omgezet in afzonderlijke zinnen, hebben we alle ingrediënten om de semantische zoekopdracht uit te voeren. De breadcrumbs zin dient als de input zin (query) en wordt vergeleken met alle HTML tabel zinnen. Om dit te doen, vectoriseren we eerst alle zinnen met behulp van een op transformator gebaseerd taalmodel. Aangezien we zinnen vergelijken, is de Sentence-BERT (SBERT) architectuur het meest geschikt. Deze architectuur is geoptimaliseerd voor het afleiden van semantisch betekenisvolle zinsinbeddingen. Er zijn talloze verfijnde BERT-modellen op deze architectuur verschenen, maar voor dit artikel gebruiken we degene die het meest is gedownload op HuggingFace: multi-qa-MiniLM-L6-cos-v1, een verfijnde variant van BERT die is geoptimaliseerd voor semantisch zoeken. Omdat dit model gebruik maakt van de SBERT-architectuur, kunnen zinnenparen eenvoudig worden vergeleken. Twee zinnen worden gevectoriseerd en hun semantische gelijkenis wordt berekend door de cosinusgelijkenis. Een waarde dicht bij 1 betekent een hoge semantische gelijkenis, terwijl een waarde dicht bij 0 een lage semantische gelijkenis betekent. Laten we de overeenkomsten berekenen van de zinnen die we tot nu toe in dit artikel hebben gemaakt.
| Sentence 1 | Sentence 2 | Semantic similarity |
|---|---|---|
| “Printing Technology Inkjet Brand HP Connectivity Technology Wi-Fi;Cloud Printing Model Name J9V92A#B1H Compatible Devices Smartphones, PC, Tablets Recommended Uses For Product Office, Home Sheet Size 3 x 5 to 8.5 x 14, Letter, Legal, Envelope Color Seagrass Printer Output Color Item Weight 5.13 pounds Product Line HP DeskJet” | “Office Products › Office Electronics › Printers & Accessories › Printers” | 0.60 (multi-qa-MiniLM-L6-cos-v1 + cosine similarity) |
| “Amazon Music Stream millions of songs Amazon Advertising Find, attract, and engage customers Amazon Drive Cloud storage from Amazon 6pm Score deals on fashion brands AbeBooks Books, art & collectibles Sell on Amazon Start a Selling Account Amazon Business Everything For Your Business AmazonGlobal Ship Orders Internationally Home …” | “Office Products › Office Electronics › Printers & Accessories › Printers” | 0.22 (multi-qa-MiniLM-L6-cos-v1 + cosine similarity) |
We zien significante verschillen in de similariteitsscores! Waar de productspecificatietabel een cosinusovereenkomst van 0,60 bereikt, heeft de niet-specificatietabel slechts een overeenkomst van 0,22 met de broodkruimels. Met deze scores kunnen we ze direct gebruiken voor retrieval door een specifieke drempelwaarde te bepalen of we kunnen deze similariteitsscores gebruiken als een nieuw kenmerk voor een classificatiemodel zoals Petrovski en Bizer (2017). We kunnen dit proces dat we zojuist hebben besproken voor elke PDP herhalen en op deze manier de productspecificaties verzamelen. Omdat onze aanpak alleen HTML-tabellen en breadcrumbs gebruikt, is deze ongevoelig voor heterogeniteit van websites, en dit maakt het een geschikte oplossing voor grootschalige geautomatiseerde e-commerce productgegevensverrijking.
Bijpassende Productspecificaties
Zodra de productinformatie is opgehaald uit verschillende bronnen, moeten we deze combineren tot één consistente lijst met specificaties die direct kan worden gebruikt. We willen geen dubbele informatie presenteren, alleen omdat verschillende specificaties verschillend zijn beschreven ondanks dat het om dezelfde specificatie gaat. Dit betekent dat we productspecificaties op elkaar moeten afstemmen. We zullen laten zien hoe hetzelfde op transformatoren gebaseerde taalmodel kan worden gebruikt om dit probleem op te lossen.
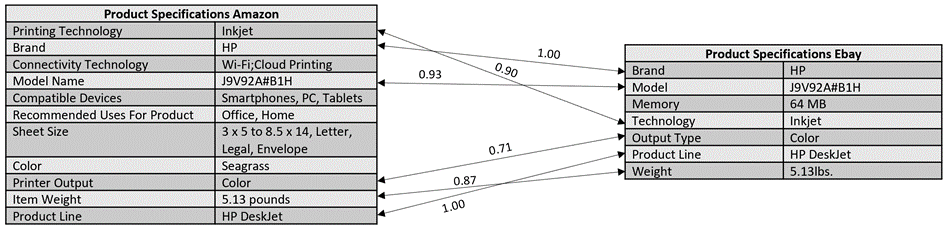
Hierboven hebben we enkele productspecificaties van Amazon en Ebay [7] gepresenteerd met betrekking tot hetzelfde product: de specifieke printer die ook in het vorige hoofdstuk is gebruikt. Amazon en Ebay beschrijven enkele identieke productspecificaties op een iets andere manier. Voor elke specificatie van de ene bron willen we de specificatie van de andere bron vinden die dezelfde betekenis vertegenwoordigt als deze aanwezig is. Het matchen van productspecificaties is in wezen een zin-gelijksoortigheidstaak en kan ook worden beschouwd als een semantische zoektaak. We benaderen de matchingtaak op een vergelijkbare manier als de detectietaak. Specifiek converteren we elke specificatie (attribuut + waarde) naar afzonderlijke zinnen die kunnen worden vergeleken. In het bovenstaande voorbeeld wordt “Printing Technology Inkjet”, dat afkomstig is van Amazon, vergeleken met “Merk HP”, “Model J9V92A#B1H”, “Geheugen 64 MB”, enzovoort, die afkomstig zijn van Ebay. We gebruikten opnieuw het multi-qa-MiniLM-L6-cos-v1 model met de cosinusovereenkomst om de semantische overeenkomst van de specificaties af te leiden. In de afbeelding hierboven hebben we de specificaties aangegeven die moeten worden gematcht en hun similariteitsscore berekend met behulp van het op transformator gebaseerde taalmodel. We zien dat dezelfde specificaties een hoge similariteitsscore behalen. Ongelijke productspecificaties hebben over het algemeen een veel lagere similariteitsscore. “Printtechnologie Inkjet” en “Merk HP”, bijvoorbeeld, geven slechts een similariteitsscore van 0,32. Het op transformatoren gebaseerde taalmodel kan dus worden gebruikt om productspecificaties te vergelijken.
Conclusie
In dit artikel hebben we de effectiviteit aangetoond van een op transformatoren gebaseerd taalmodel voor grootschalige geautomatiseerde verrijking van e-commerce productgegevens. Specifiek hebben we een oplossing geboden voor het detecteren van productspecificaties die onafhankelijk is van de websitestructuur. We benaderden het detectieprobleem als een semantische zoektaak en waren in staat om de specificaties op te halen door de gelijkenis van de tabellen met de broodkruimels te berekenen. Ten tweede toonden we aan dat het op transformatoren gebaseerde taalmodel ook identieke productspecificaties kan matchen ondanks syntactische discrepanties. Al met al zijn transformator-gebaseerde taalmodellen zeer krachtig en kunnen ze worden toegepast op een grote verscheidenheid aan NLP-taken. Zoals we in dit artikel hebben laten zien, omvat dit ook semantisch zoeken (of zinsgelijkenis) voor grootschalige geautomatiseerde verrijking van e-commerce productgegevens.
