Insights
Optimalisatie van Winkelen met AI Chatbot en LLM Technologieën

In de huidige digitale context zijn bedrijven continu op zoek naar manieren om online interacties toegankelijker te maken. Veel online shoppers ervaren obstakels bij het vinden van relevante informatie en hulp betreffende de producten die ze willen. In tegenstelling tot fysieke winkels, waar een gesprek met een medewerker kan helpen bij het vinden van de juiste producten, kunnen online gebruikers overweldigd raken door een grote hoeveelheid informatie.
Een initiatief van Squadra Machine Learning Company richt zich op het dichten van deze kloof door een persoonlijke winkelassistent te introduceren die is afgestemd op de specifieke behoeften van de gebruiker. Het doel is om de totale klantervaring te verbeteren door in te spelen op de tekortkomingen van algemene online interacties. Deze oplossing bestaat uit een chatbot, ontwikkeld met een groot taalmodel (LLM) en verrijkt met relevante informatie. Hiervoor wordt de techniek ‘Retrieval-Augmented Generation’ (RAG) toegepast. Hoewel deze chatbot oorspronkelijk is ontworpen voor een hardwarewinkel, kan hij ook worden aangepast aan andere sectoren.
De chatbot opereert als een AI-assistent, waardoor gebruikers kunnen chatten, productinformatie kunnen aanvragen en ondersteuning kunnen krijgen bij hun doe-het-zelf projecten. De centrale vraag van dit onderzoek is: “Hoe kan de effectiviteit van een door AI aangestuurde chatbot geoptimaliseerd worden om gebruikers beter te helpen met het verkrijgen van informatie over DIY-projecten en productaanbevelingen?”.
Door deze vraag te adresseren, hopen we praktisch inzicht te verschaffen in hoe AI-aangedreven chatbots effectiever gemaakt kunnen worden, resulterend in een meer gebruiksvriendelijke en ondersteunende online winkelervaring.
Product
De chatbot benut een LLM om vragen van gebruikers te beantwoorden. Daarnaast maakt hij gebruik van productinformatie en expertblogs die zijn opgeslagen in een vector database. Het eindproduct is een prototype dat het potentieel van generatieve AI in de e-commerce sector illustreert. Een voorbeeld van hoe de chatbot functioneert, wordt hieronder weergegeven.
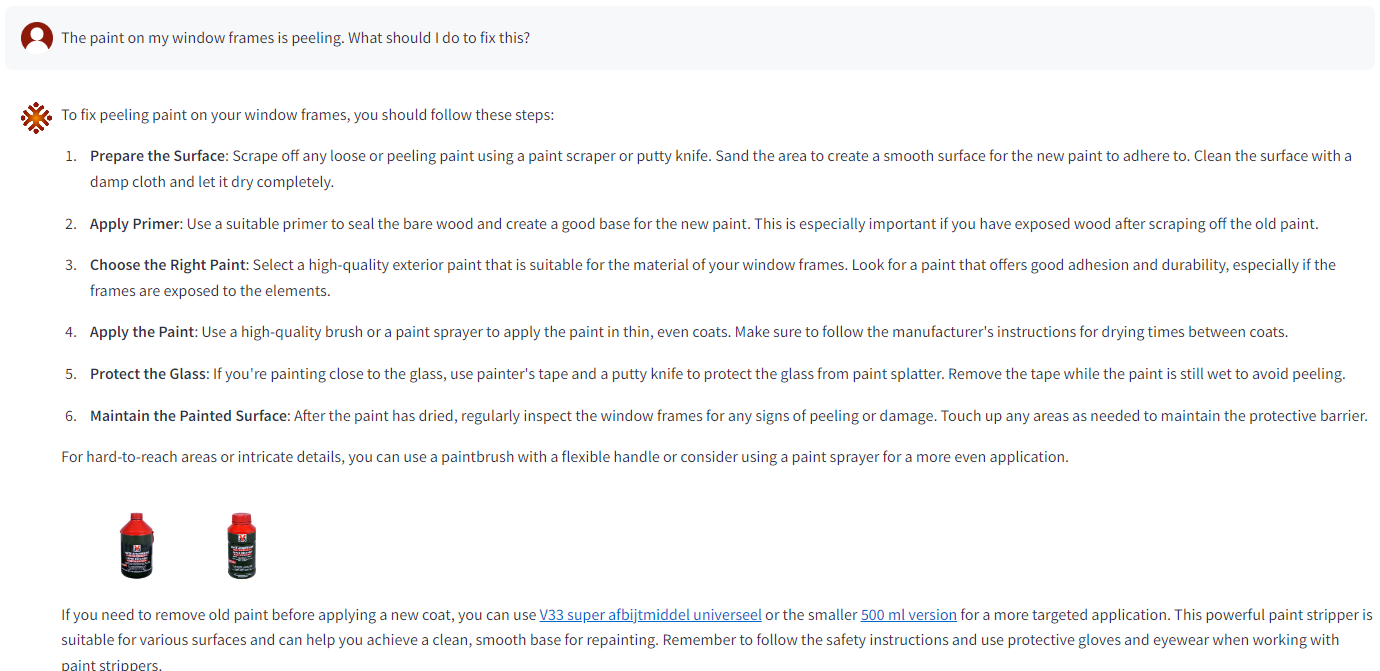
Zoals zichtbaar is, biedt het antwoord verschillende links naar relevante producten en eindigt het met een link naar een blogpost voor meer informatie.
Workflow
Om een beter begrip te krijgen van de werking van de chatbot en de impact op gebruikersinteracties, bekijken we de stappen die nodig zijn om gepersonaliseerde informatie te verstrekken:
- Gebruikersquery Indienen: Het proces begint wanneer een gebruiker een vraag stelt aan de chatbot over doe-het-zelfprojecten of productaanbevelingen.
- Queryverfijning: De chatbot verduidelijkt de vraag van de gebruiker door een verzoek te verzenden naar de OpenAI API, met de chatgeschiedenis als context.
- Queryclassificatie: Er wordt een verzoek naar de OpenAI API gestuurd om de verfijnde vraag in specifieke categorieën te classificeren, zoals ‘aanbevelingen’, ‘vergelijkingen’, ‘stapsgewijze handleidingen’, ‘beschikbaarheid’ of ‘overig’.
- Productopvraging: De chatbot haalt de meest relevante producten op uit de vector database die aansluiten bij de vraag van de gebruiker. Deze stap waarborgt dat de chatbot nauwkeurige en context-specifieke productaanbevelingen doet.
- Blogopvraging: Gelijktijdig zoekt de chatbot het meest relevante blog dat gerelateerd is aan de vraag van de gebruiker uit de vector database en haalt het ook relevante blogfragmenten op.
- Specificatiegeneratie: De chatbot verstuurt een verzoek naar de OpenAI API om een lijst met productspecificaties op te stellen op basis van de vraag van de gebruiker en de opgehaalde blogs.
- Aanvullende Productopvraging: Voor iedere genoemde productspecificatie verfijnt de chatbot de informatie door extra producten op te halen die nauw aansluiten bij de vraag van de gebruiker vanuit de vector database.
- Responsgeneratie: Ten slotte wordt er een verzoek naar de OpenAI API verzonden om een uitgebreid antwoord op de vraag van de gebruiker te formuleren. De chatbot gebruikt de geclassificeerde vraag, de bloginformatie en de productgegevens om een gedetailleerd en contextueel rijk antwoord te creëren.
Modelontwikkeling
Om de vooruitgang in de prestaties van de chatbot te evalueren, passen we een systematische aanpak toe die gebaseerd is op het ontwikkelen van verschillende versies. Deze methode maakt een gemakkelijke vergelijking tussen versies mogelijk en stelt ons in staat om voort te bouwen op de successen van eerdere iteraties.
Conclusie
Om de AI-aangedreven chatbot voor doe-het-zelf projecten en productaanbevelingen te optimaliseren, hebben we verschillende versies doorlopen. Strategieën zoals prompt engineering en vraagclassificatie zijn ingezet om gebruikersinteracties te verbeteren. Het balanceren van complexiteit en efficiëntie omvatte zorgvuldige modelselectie en dataverwerking voor kosteneffectiviteit. Latere versies hebben snelheid geprioriteerd door informatie te vereenvoudigen, en de meest geoptimaliseerde versie benut model-finetuning voor verhoogde efficiëntie.
De resultaten maken duidelijk dat een krachtige nadruk op prompt engineering leidt tot aanzienlijke verbeteringen in de prestaties van de chatbot. Verbeteringen in economische overwegingen benadrukken de noodzaak om verder te denken dan alleen nauwkeurigheid. Het finetunen van het model blijkt een effectieve manier om de prestaties te verbeteren, terwijl kosten en tijdsinvestering laag blijven.

Emma Beekman
Data Science Stagiaire bij Squadra Machine Learning Company
