Insights
Het Recept voor Parafraseren met T5

Transformer gebaseerde modellen zijn snel de standaard geworden voor veel Natural Language Processing (NLP) taken, met OpenAI’s GPT-3 als een van de meest prominente voorbeelden. Deze modellen kunnen schrijvers ondersteunen bij diverse taken en een aanzienlijk aantal arbeidsintensieve en handmatige verantwoordelijkheden verlichten.
Stel je voor dat je een retailer bent die verscheidene varianten van hetzelfde product aanbiedt. Je hebt voor je website een productbeschrijving nodig om klanten aan te trekken, en voor SEO-doeleinden is het niet ideaal om dezelfde beschrijving voor elk vergelijkbaar product te gebruiken. Het kan leuk zijn om creatief te zijn met het schrijven van een aantrekkelijke productbeschrijving, maar het herschrijven van deze tekst in 10 iets afwijkende versies is minder plezierig en eerder repetitief. In deze blog leggen we uit hoe je een model kunt trainen dat automatisch parafrases uit een gegeven zin genereert.
Als je dit artikel leest omdat je geïnteresseerd bent in NLP, heb je waarschijnlijk al eens gehoord van de transformer. Mocht dat niet het geval zijn, dan geven we je een beknopte uitleg. De transformer is een type neurale architectuur die bijzonder effectief is voor sequentiemodellering[^1]. Transformers hebben een encoder-decoder structuur, die geen gebruik maakt van de gebruikelijke recursies en convoluties, maar uitsluitend vertrouwt op zelf-attentiemechanismen. Deze zelf-attentie stelt het model in staat om de volledige inputsequentie in één keer te bekijken en biedt het een langdurig geheugen, veel groter dan dat van andere neurale architecturen.
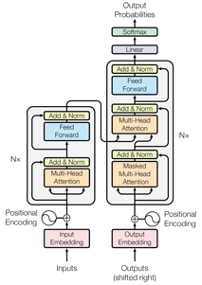
Met deze transformerarchitectuur zijn verschillende veelzijdige taalmodellen ontwikkeld die de toonaangevende keuzes zijn voor een breed scala aan natuurlijke taalverwerkings- en generatietaken. We kunnen de originele transformerarchitectuur beschouwen als pastadeeg en alle daarop gebaseerde modellen als verschillende vormen van pasta met elk hun eigen functie. De keuze van onze pastavorm beïnvloedt de type saus die we gebruiken. Niet elke saus past bij elke vorm, net zoals verschillende transformer-gebaseerde modellen verschillende NLP taken ondersteunen. Het BERT-model van Google is uitsluitend opgebouwd uit encoderblokken van de originele transformer en presteert uitstekend bij taken zoals vraag-antwoord. Aan de andere kant zijn de modellen in de GPT-reeks opgebouwd uit alleen het decoderdeel van de transformer en zijn zij bijzonder goed in het genereren van natuurlijke taal.
Voor het kiezen van onze pastavorm moeten we nadenken over onze parafraseringssaus. Een set parafrases bestaat uit twee zinnen die dezelfde betekenis hebben maar andere woorden gebruiken. Voor onze taak houdt dit in dat we een inputzin omzetten in een andere zin, terwijl de betekenis van de originele zin behouden blijft. Dit verschilt van vraag-antwoord taken en vereist daarom een andere pasta-variant. Aangezien we de ene tekst in een andere omzetten, werkt een model met een encoder-decoder structuur het beste. Daarom kiezen we T5 om ons parafraseringsinstrument te bouwen.
T5
De Text-to-Text Transfer Transformer (T5) van Google heeft een encoder-decoder structuur die vrijwel identiek is aan die van de originele transformer, en is getraind op 750 GB aan gevarieerde teksten[^2]. Dit model komt in verschillende formaten, en in dit artikel zullen we de kleinste voorgetrainde versie van 60 miljoen parameters verfijnen met behulp van de Huggingface Transformers bibliotheek.
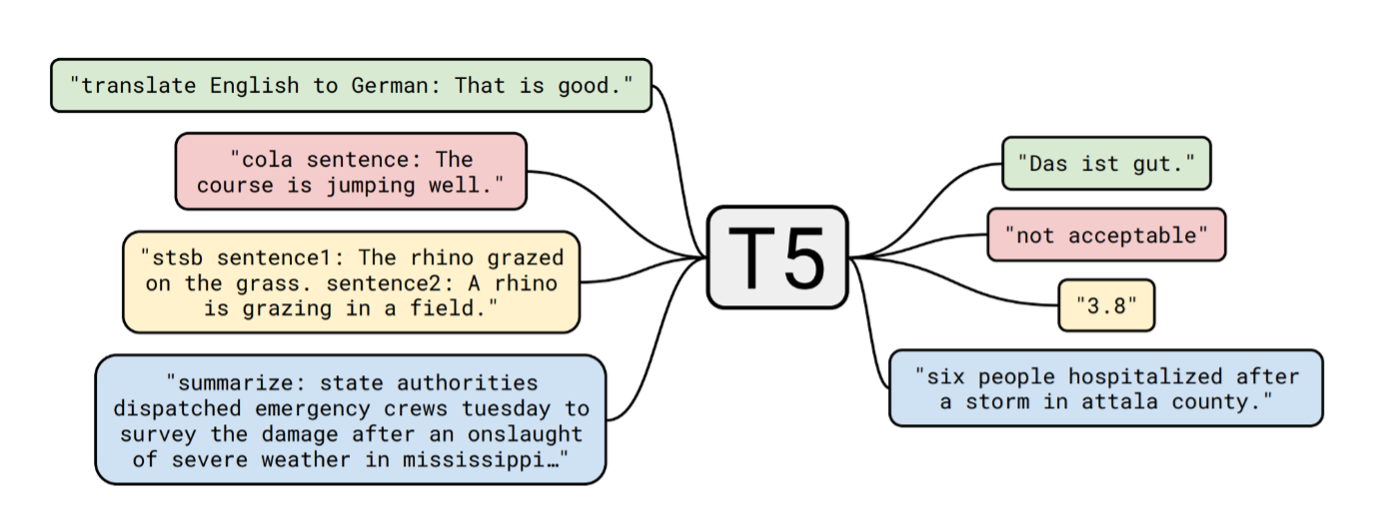
Om één model breed toepasbaar te maken voor meerdere taken, behandelt T5 elke downstream NLP taak als een tekst-naar-tekst probleem. Voor trainingsdoeleinden geeft T5 aan dat elk voorbeeld een input en een doel heeft. Tijdens de pre-training worden de inputs vervormd door het maskeren van woordreeksen die dienen als doel voor de voorspelling van het model. Tijdens de finetuning blijft de input intact, en is het doel de gewenste output.
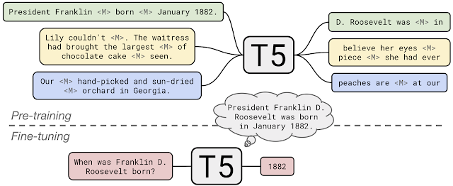
Om het model voor verschillende doeleinden te gebruiken, wordt in de fase van finetuning een voorvoegsel aan de input toegevoegd dat aangeeft voor welke taak het model specifiek traint. In ons geval zijn de input-output paren parafrases, dus voegen we het voorvoegsel “parafrase:” toe aan elke input. Na de verfijning zal het model deze voorvoegsels herkennen en de bijbehorende taken, zodat het een parafrase genereert wanneer de invoer met “parafrase” begint, in plaats van bijvoorbeeld een vertaling.
Gegevens
Laten we de ingrediënten voor onze saus samenstellen. Om ervoor te zorgen dat ons model voldoende data heeft om van te leren, combineren we drie openbaar beschikbare datasets met Engelse parafrase-paren:
- The Paraphrase Adversaries from Word Scrambling dataset gebaseerd op Wikipedia-inhoud (PAWS-Wiki)
- The Microsoft Research Paraphrase Corpus (MSRP)
- The Quora Question Pairs dataset
De items in deze datasets zijn oorspronkelijk geclassificeerd als parafrases of niet-parafrases, dus voor ons doel kunnen we de niet-parafrases eruit filteren. We komen op een totaal van 146.663 parafrase-paren. De Quora Vragenparen dataset is echter vier keer zo groot als de gecombineerde PAWS-Wiki en MSRP datasets. Het trainen van de modellen met zoveel vragen kan leiden tot een overrepresentatie van vraagvormen, omdat het merendeel van de input uit vragen bestaat. Daarom creëren we een gebalanceerde uiteindelijke dataset met een gelijke verdeling van vragen en niet-vragen. Deze uiteindelijke dataset bevat 65.608 paren van parafrases, die worden verdeeld in train-, test- en validatiesets in een verhouding van respectievelijk 0.8, 0.1 en 0.1.
Output Filtering
Zoals eerder genoemd, betekent parafraseren het omzetten van een zin in een andere zin, met behoud van de betekenis. Dit creëert twee vereisten voor de resultaten. Ten eerste moeten de input en output semantisch zo dicht mogelijk bij elkaar liggen. Ten tweede moet er voldoende variatie zijn in het gebruik van woorden. Twee exacte zinnen liggen semantisch dicht bij elkaar, maar ze parafraseren elkaar niet. Eveneens, het volledig veranderen van de woorden in een zin kan de originele nuance veranderen, wat het behouden van de betekenis bemoeilijkt. Deze twee vereisten vormen ons ‘zout en peper’. Een goede balans tussen beide leidt tot een positief resultaat.
Om de semantische afstand tussen de input en output te meten, gebruiken we Google’s Universal Sentence Encoder (USE) om een representatie van elke zin te creëren. Deze representaties zijn 512-dimensionale vectoren die zo zijn ontworpen dat gerelateerde zinnen dichter bij elkaar staan in de vector ruimte. We kunnen dan de cosinusgelijkenis tussen de vector van de input en de vector van de output berekenen, wat hun semantische gelijkenis weergeeft in een schaal van 0 tot 1. Hoe hoger de waarde, des te nauwer verwant zijn de twee zinnen.
Om de verschillen in structuur te kwantificeren, hanteren we twee maatstaven. ROUGE-L meet de langste gemeenschappelijke subsequence van woorden tussen de input en output. BLEU vertegenwoordigt de n-gram precisie op woordniveau. Bij beide maatstaven krijgen identieke zinnen een score van 1 en zinnen zonder enige overlap ontvangen een score van 0. Om ervoor te zorgen dat de output niet te veel op de input lijkt, stellen we een maximumwaarde in die deze metingen kunnen behalen. Zinnen met een ROUGE-L score of een BLEU score boven de gestelde grens worden verworpen. We stellen deze cutoff-waarden in op 0.7, maar je kunt dit naar eigen voorkeur aanpassen.
Nadat de resultaten zijn gefilterd, rangschikken we de overgebleven uitkomsten op basis van hun USE-score, en kiezen we de uitkomst met de hoogste score als de beste parafrase.
Resultaten
Nu we ons kookproces hebben afgerond, is het tijd om te proeven! Voor elke input genereert het model 10 mogelijke parafrases. Vervolgens filteren en rangschikken we deze op basis van de USE, ROUGE-L en BLEU scores. De zin met de hoogste score is onze resulterende parafrase. Hier zijn enkele voorbeelden van parafrases die met ons model zijn gegenereerd.
| # | Input | Output | USE | R-L | BLEU |
|---|---|---|---|---|---|
| 1 | Having won the 2001 NRL Premiership, the Knights traveled to England to play the 2002 World Club Challenge against Super League champions, the Bradford Bulls. | The Knights came to England for the World Club Challenge 2002 against the Bradford Bulls, the Super League champions after winning the 2001 NRL Premiership. | 0.9611 | 0.4651 | 0.2411 |
| 2 | Is tap water in Italy good for drinking? | Is tap water good for drinking in Italy? | 0.9641 | 0.6250 | 0.3083 |
| 3 | Make sure you have the right gear when you explore the nature. | When exploring nature, make sure you have the right gear. | 0.8350 | 0.5999 | 0.3887 |
Deze resultaten zijn behoorlijk veelbelovend. Voorbeelden 2 en 3 zijn parafrases waarbij de woordvolgorde van de inputzin is aangepast, wat ook blijkt uit de relatief hogere ROUGE-L en BLEU scores. Voorbeeld 1 laat een goede balans zien tussen semantische overeenkomst en verschil in woordgebruik. De structuur is volledig verschillend en de semantische overeenkomst is extreem hoog. Ons parafraseringsmodel is een recept voor succes!
Referenties
[^1]: A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser en I. Polosukhin, „Attention Is All You Need,” Advances in neural information processing systems, pp. 5998-6008, 2017. [^2]: C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Metana, Y. Zhou, W. Li en P. Liu, „Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,” Journal of Machine Learning Research, vol. 21, nr. 140, pp. 1-67, 2020.
