Case
Euronics
Laatst gewijzigd op 20 maart 2026 • 3 min leestijd
- Matchen van datasets
- Verhoogde datakwaliteit
- Consistenter datamodel
Euronics is een organisatie van bedrijven die consumentenelektronica aanbieden. Met meer dan 11.000 onafhankelijke elektronicawinkels verspreid over 37 landen, heeft deze vereniging een aanzienlijk marktaandeel in de consumentenelektronicabranche. Hoewel deze internationale reikwijdte bijdraagt aan het succes, brengt het ook enkele uitdagingen met zich mee. Het bedrijf gebruikt in totaal 19 PIM-systemen en heeft 54 afzonderlijke webwinkels voor consumenten. Door deze diversiteit aan data en PIM-systemen kan de productinformatie soms inconsistent en onvolledig zijn. Om dit issue aan te pakken en de efficiëntie te verhogen, werd besloten om alle beschikbare productinformatie uit de verschillende PIM-systemen te integreren. De grootste uitdaging was echter dat ze niet precies wisten hoe ze dit moesten realiseren.
Uitdaging
Het bleek dat sommige landen beschikten over meer en beter gestructureerde productdata dan andere landen. In landen waar de datakwaliteit en -kwantiteit tekortschoten, was het mogelijk om de bestaande, kwaliteitsvollere data uit andere landen te gebruiken om deze te verbeteren. Dit vereiste dat productcodes zoals EAN, UPS en GTIN aan elkaar gekoppeld werden. Aangezien deze codes per land kunnen verschillen, maakte dit het proces aanzienlijk complex en bijna onuitvoerbaar. De datasets uit diverse landen bleven inconsistent en in sommige gebieden was de datakwaliteit absoluut onvoldoende. Euronics moest dus nadenken over alternatieve oplossingen, en hier bood Squadra Machine Learning Company ondersteuning bij het vinden van een geschikte aanpak.
Oplossing
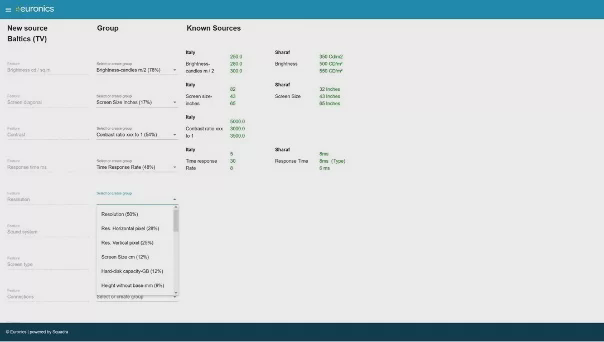
Squadra Machine Learning Company stelde voor om afzonderlijke producten aan elkaar te koppelen op basis van productkenmerken. Eerst werden de datasets van drie retailers verzameld en de eigenschappen binnen deze datasets gematcht. Daarna werden deze eigenschappen in kaart gebracht om meer inzicht te krijgen. Vervolgens werd er onderzocht of het mogelijk was om de productcodes en modelnummers te matchen, en het bleek dat de modelnummers wel gekoppeld konden worden. Daarna werden de beschikbare productkenmerken gematcht (zie onderstaande screenshot). Vervolgens werd er een algoritme ontwikkeld dat gebaseerd was op de merknaam en productcode. De volgende stap was het aanvullen van onvolledige datasets door gebruik te maken van de completere datasets. Door middel van de slimme tool werd er een gelijkheidsscore tussen producten gepresenteerd, wat inzicht gaf in de overeenkomsten tussen datasets. Wanneer een nieuwe dataset wordt toegevoegd, biedt deze gelijkheidsscore informatie over de gelijkenissen met andere sets. Het is ook mogelijk om de nieuwe dataset aan te vullen wanneer deze onvoldoende data heeft.
Resultaat
Na de samenwerking met Squadra Machine Learning Company heeft Euronics de consistentie tussen haar verschillende afdelingen aanzienlijk verbeterd. Dit resulteert in betere informatie voor klanten en verhoogt de consistentie en de kwaliteit van de data, waardoor het merk meer inzicht krijgt in de waarde van gecombineerde gegevens. Dit kan gezien worden als een eerste stap naar nieuwe mogelijkheden: met het nieuwe consistente datamodel kan het merk beter in kaart brengen welke producten in welke regio’s verkocht worden. Ook zou het mogelijk zijn om leveranciers te verzoeken meer productgegevens aan te leveren. Indien deze informatie optimaal gebruikt wordt, ontstaan er kansen voor het automatiseren van bedrijfsprocessen. Bijvoorbeeld, Powertext.ai kan unieke en kwalitatieve productbeschrijvingen genereren op basis van producteigenschappen. Dit leidt tot betere vindbaarheid op Google, waardoor klanten eenvoudiger naar jouw website worden geleid, en de kans op conversie vergroot. In combinatie met de verbeterde informatie die aan klanten wordt geboden, kan dit de klantervaring aanzienlijk verbeteren.
