Insights
Verbetering van de Automatische Productclassificatie voor E-Commerce met Beeldherkenning

E-commerce is booming, het gebied van machine learning wordt steeds volwassener en het is dan ook geen wonder dat deze twee gebieden meer dan ooit met elkaar verweven raken. Voor consumenten is dit het vaakst merkbaar via productaanbevelingen, die worden aangestuurd door intelligente algoritmen. Een minder opvallend aspect dat e-commerce drijft, is de mogelijkheid om het zoeken voor consumenten te vergemakkelijken, dat wil zeggen dat consumenten de producten kunnen vinden die ze zoeken (op de plaats waar ze het zouden verwachten). Achter de schermen worden deze producten opgeslagen in e-catalogi, ook wel het product informatie management (PIM) systeem genoemd. Dit brengt ons bij het fenomeen van producttaxonomieën, boomstructuren die verantwoordelijk zijn voor het indelen van de verschillende producten in hun respectievelijke categorieën. Deze taxonomieën kunnen grafisch worden weergegeven als een hiërarchische structuur (Kim, Lee, Chun, & Lee, 2006), zoals weergegeven in figuur 1.
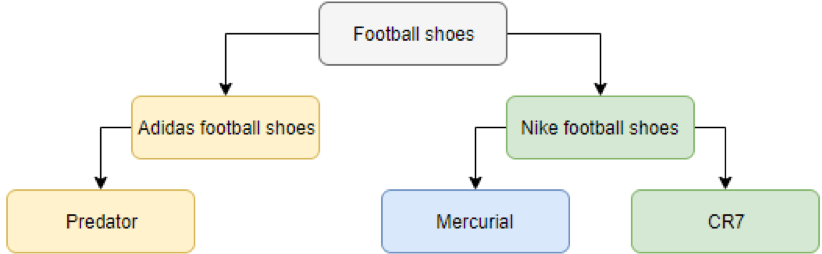
Een producttaxonomie beperkt zich simpelweg tot de verschillende subcategorieën binnen categorieën, wat in de bovenstaande figuur een klant bijvoorbeeld naar alle Adidas Predator voetbalschoenen zou leiden. Een van de belangrijkste sterke punten van e-commercebedrijven is hun vrijwel oneindige schapruimte, waardoor consumenten door een immens aantal producten kunnen bladeren (Elberse, 2008). Maar, zoals je misschien al hebt bedacht, moeten deze producten eerst allemaal worden gecategoriseerd in de taxonomie. Voor veel bedrijven is dit nog steeds een handmatige taak die wordt uitgevoerd door hun werknemers, wat veel tijd in beslag kan nemen. Steeds meer bedrijven maken echter de overstap naar geautomatiseerde productclassificatie, dat wil zeggen dat ze gebruik maken van kunstmatige intelligentie om de classificatietaak voor je uit te voeren. Om specifieker te zijn, machine learning wordt toegepast. Met andere woorden, deze bedrijven besteden deze taak uit aan bedrijven die gespecialiseerd zijn in machine learning, bedrijven zoals het onze! Door het classificatieproces te automatiseren kan een enorme tijd- en dus kostenbesparing worden gerealiseerd.
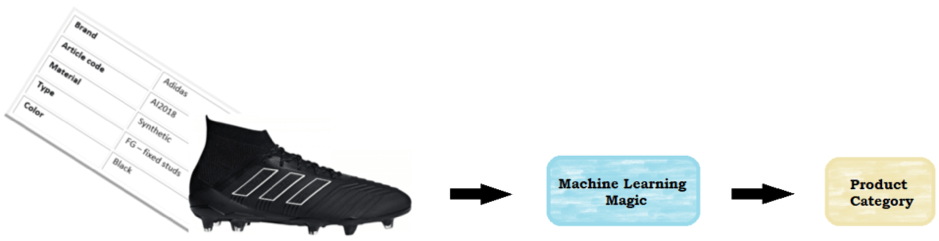
Onlangs hebben we een van onze nieuwste algoritmen toegepast op de productclassificatietaak voor een bedrijf dat ons niet alleen tekstuele productgegevens kon leveren, maar ook de afbeelding van elk product. In het algemeen worden de meeste productclassificatietaken uitgevoerd met alleen tekstuele gegevens, vanwege de bevredigende prestaties die deze aanpak levert. Het gebruik van afbeeldingen in combinatie met tekstuele productinformatie is echter veelbelovend! Door een hybride aanpak te gebruiken, waarbij verschillende algoritmen worden gecombineerd om de tekst- en beeldgegevens te verwerken, kan de classificatieprestatie worden verbeterd.
Je vraagt je misschien af: “Waarom is het nodig om verschillende algoritmen te combineren om de classificatietaak uit te voeren? Wel, dit heeft te maken met de heterogene aard van de data, ook wel multimodaal leren genoemd (Lahat, Adali, & Jutten, 2014; Ngiam, Khosla, Kim, Nam, Lee, & Ng, 2011). Srivastava en Salakhutdinov (2012) wijzen treffend op het verschil tussen deze soorten data: “Tekst wordt meestal weergegeven als discrete, schaarse vectoren voor het tellen van woorden, terwijl een afbeelding wordt weergegeven aan de hand van pixelintensiteiten of outputs van functie-extractoren die reële waarden en dichtheid hebben” (p.1). Daarom is een aanpak nodig die deze gegevensbronnen gelijkwaardig of complementair maakt. Complementariteit is een van de kenmerken van multimodale gegevens, wat betekent dat elke gegevensbron waarde toevoegt aan het geheel, wat niet kan worden afgeleid uit een enkele bron (Lahat et al., 2014). Om de intuïtie achter multimodaliteit samen te vatten, streven we dus naar synergie tussen bronnen, waarbij het geheel groter is dan de som van de delen.
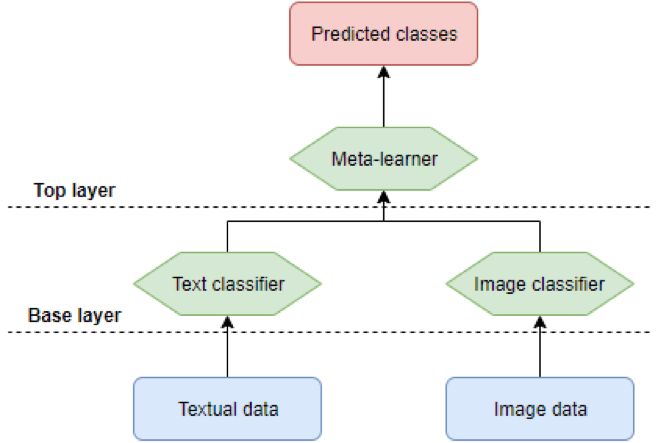
De hybride aanpak die verantwoordelijk is voor het bereiken van synergie tussen tekst en beeld kan worden voorgesteld als een piramide, met een basis- en toplaag. De basislaag bestaat uit twee algoritmen, één specifiek voor tekstgegevens en één specifiek voor beeldgegevens. De resultaten van deze basislaag vloeien naar de toplaag, bestaande uit één algoritme, dat ons de uiteindelijke voorspellingen van productklassen geeft. Een eenvoudige weergave van het hybride model is te zien in figuur 3, een meer diepgaande uitwerking volgt later.
De bovenstaande weergave laat eenvoudig zien dat we twee afzonderlijke invoergegevens hebben, die beide worden ingevoerd door een andere classificeerder. De uitvoer van beide classificeerders wordt toegevoerd aan een meta-learner, wat een ander classificatiealgoritme is, en uiteindelijk is de uitvoer van dit laatste algoritme de voorspelde klassen voor de producten.
Wat we eigenlijk gevisualiseerd zien in figuur 3 is een voorbeeld van een ensemblemodel. Ensemble modellen komen voort uit het vakgebied van ensemble leren (Džeroski & Ženko, 2004), dat zich richt op het maken van ensemble modellen op basis van bestaande classifiers. Vanuit een niet-technisch aspect kunnen ensemblemodellen worden vergeleken met de menselijke geest. Wanneer we een belangrijke beslissing moeten nemen, evalueren we vaak verschillende standpunten voordat we een sluitend antwoord geven. Een soortgelijk soort redenering ligt ten grondslag aan ensemblemodellen, aangezien “het belangrijkste idee achter de ensemblemethodologie is om verschillende individuele classificeerders te wegen en deze te combineren om een classificeerder te verkrijgen die beter presteert dan elk van hen” (Rokach, 2010, p. 1). Met een ensemblemodel willen we dus beter presteren dan de individuele classifiers waarop het is gebaseerd. Dat is precies wat wij als bedrijf willen bereiken, een betere service bieden aan onze klanten, met alle mogelijke middelen!
Het vakgebied van ensembleleren kent verschillende architecturen om een ensemble te vormen, zoals bagging, boosting en stacking. Op dit moment zal alleen stacking worden besproken, maar er kan een overvloed aan informatie worden gevonden over de eerste twee architecturen met een snelle Google search . Laten we verder gaan met stacking, de ensemblearchitectuur die we gebruiken voor onze productclassificatietaak. In een stapelend ensemble worden de outputs van de classificeerders van de basislaag gebruikt als inputs voor de classificeerder in de bovenste laag. De classificeerders van de basislaag kunnen heterogeen zijn (Graczyk, Lasota, Trawínski, & Trawínski, 2010), in de zin dat verschillende modellen en dus verschillende datasets kunnen worden gebruikt. De outputs die worden gegenereerd door de classificeerders op basisniveau zijn ofwel de voorspelde klasse van elk product, ofwel de waarschijnlijkheid dat het product bij elke mogelijke klasse hoort. Een voorbeeld van elke output wordt getoond in de onderstaande tabel.
| Product information | Class 1 - Adidas Predator football shoes | Class 2 | Class 3 | Class 4 | Class 5 |
|---|---|---|---|---|---|
| Adidas, AI2018, Synthetic, FG – fixed studs, Black | 1 | 0 | 0 | 0 | 0 |
| Adidas, AI2018, Synthetic, FG – fixed studs, Black | 0.80 | 0.30 | 0.10 | 0.20 | 0.01 |
Figuur 4: De twee mogelijke soorten uitgangen {.small}
Onze Aanpak
Zoals je kunt zien, kan de uitvoer van de classificeerders op basisniveau alles of niets zijn, wat betekent dat ze die ene klasse voorspellen waartoe een product volgens hen behoort, of ze kunnen de waarschijnlijkheid voor elke mogelijke klasse teruggeven. De volgende stap is dat deze outputs de input vormen voor de meta-learner. Dit betekent dat de voorspellingen voor elke klasse, in een van de twee formaten hierboven, worden gebruikt als invoer. In het bovenstaande voorbeeld hebben we 5 verschillende klassen, wat zou betekenen dat de invoer bestaat uit deze 5 kenmerken. Op basis van deze kenmerken worden de uiteindelijke voorspellingen gedaan. Door deze stappen te volgen, hebben we tekstuele gegevens en afbeeldingsgegevens gecombineerd en zo een synergie tot stand gebracht die heeft geleid tot een verbeterde productclassificatieservice!
Zoals u inmiddels begrijpt, gebruikt ons ensemblemodel voor elk gegevenstype een andere classifier en daarbovenop nog een classifier om beide gegevenstypen te combineren. In de komende paragrafen zal elke classifier verder worden uitgewerkt om onze aanpak in meer detail te beschrijven.
Tekstclassificator
De tekstgegevens die voor ons beschikbaar zijn, kunnen relatief eenvoudig worden geclassificeerd met eenvoudige algoritmen zoals k-nearest neighbors of met complexere algoritmen zoals neurale netwerken. In onze benadering hebben we een opstelling gemaakt waarbij verschillende classificeerders worden geëvalueerd en de best presterende wordt gekozen (in termen van uiteindelijke nauwkeurigheid van het volledige ensemblemodel) om te worden gebruikt als tekstclassificeerder in het ensemblemodel. In de praktijk betekent dit dat bijvoorbeeld logistische regressie alleen het beste presteert, maar bij het voorspellen met het volledige ensemblemodel wordt de hoogste uiteindelijke nauwkeurigheid bereikt wanneer k-nearest neighbors wordt gebruikt als tekstclassificator.
Om deze algoritmen te gebruiken voor classificatie, moeten verschillende tekstvoorbereidingsstappen worden toegepast. Voor tekstclassificatietaken is het gebruikelijk om de bag-of-words (BoW) methode te gebruiken, wat simpelweg een ‘bag’ is van alle unieke woorden die voorkomen in de dataset. Om ervoor te zorgen dat we de meest informatieve woorden in deze bag opnemen, manipuleren we eerst de tekst door stopwoorden te verwijderen, lemmatisering toe te passen en meer van dit soort praktijken. Dit leidt tot een meer informatieve BoW, en zou dus moeten leiden tot een verbeterde classificatienauwkeurigheid. Om de woorden in de zak informatiever te maken, worden bekende methoden zoals CountVectorizer en TfidfTransformer toegepast. De eerste telt simpelweg het voorkomen van elk woord per product, terwijl de tweede een gewogen frequentiescore berekent op basis van het voorkomen van elk woord per product en het voorkomen van ditzelfde woord in alle producten. Het trainen en testen van elke classifier gebeurt via een typische opstelling, zoals in figuur 5 ( Credits ).
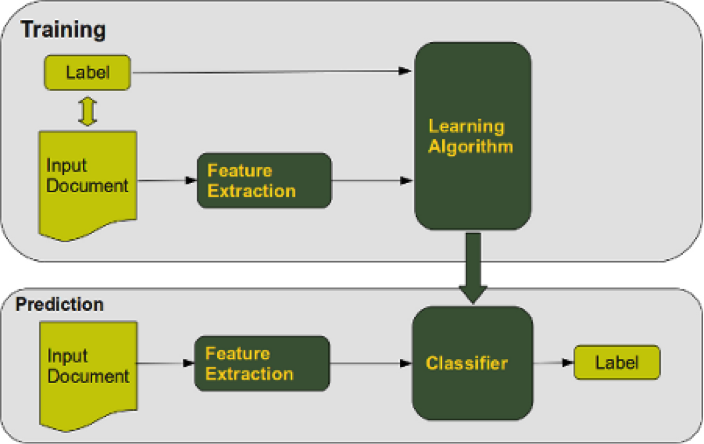
In deze opzet komt het label overeen met de productcategorie, is het invoerdocument de tekstuele productinformatie en zijn de kenmerken de unieke woorden in elke zin (weergegeven via hun TF-IDF-score). Een bijzonderheid is het gebruik van de One-Versus-Rest (OVR) methode, wat betekent dat het classificeren van een product gebeurt via de intuïtie van één klasse tegen alle andere klassen. Dit is anders dan de standaardaanpak waarbij elke klasse wordt vergeleken met elke andere klasse. Dus in plaats van te vragen: “Behoort dit product tot klasse A, B, C of D?”, is de vraag nu: “Behoort dit product tot klasse A of een van de andere klassen?”.
Zodra de classifier is getraind en getest, worden er daadwerkelijke voorspellingen gedaan op de validatiedataset. De voorspellingen kunnen de vorm hebben van een werkelijke voorspelling of een waarschijnlijkheid voor elke klasse (zoals eerder vermeld). In ons geval zagen we dat de waarschijnlijkheden leidden tot een hogere nauwkeurigheidsscore van het ensemblemodel, dus gebruiken we de waarschijnlijkheden voor elke klasse per product als invoer voor de meta-learner.
Beeldclassificator
De volgende is de afbeeldingsdataset. Voor dit gegevenstype hebben we een vrij complex algoritme voor classificatie gekozen. De enorme vooruitgang die de laatste jaren is geboekt op het gebied van computervisie is vooral te danken aan verschillende neurale netwerkarchitecturen zoals AlexNet , die de hernieuwde belangstelling voor neurale netwerken hebben aangewakkerd, en de laatste tijd ook aan netwerken zoals Inception Resnet V2 . Deze modellen zijn superieur voor de meeste taken in vergelijking met ouderwetse benaderingen waarbij bijvoorbeeld logistische regressie wordt gebruikt.
Een obstakel dat moet worden overwonnen bij het gebruik van deze modellen is het feit dat ze enorme hoeveelheden afbeeldingen nodig hebben om te trainen, in de orde van duizenden per klasse. Onze klant kwam daar met hun dataset niet bij in de buurt, met klassen die hooguit honderden producten bevatten, maar ook veel klassen met minder dan honderd producten. Modellen zoals AlexNet zijn echter voorgetraind op miljoenen afbeeldingen uit duizenden klassen. Daarom zijn de parameters voor kenmerkextractie goed getraind, waardoor we een techniek kunnen gebruiken die transfer learning wordt genoemd. Zie figuur 7 ( Credits ).
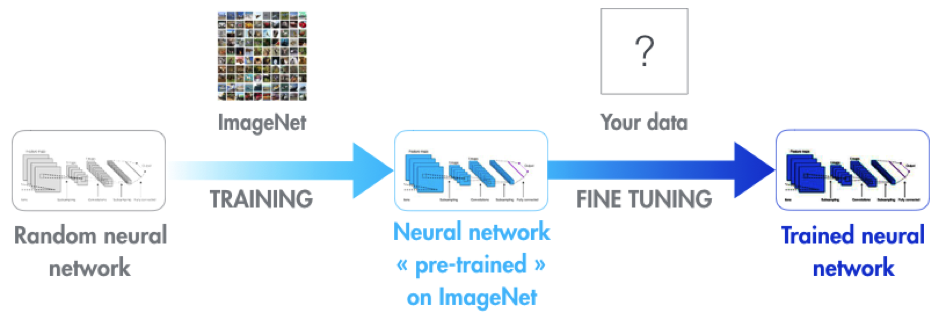
In het kort betekent dit dat we zo’n voorgetraind model kunnen hergebruiken en toepassen op een nieuwe dataset (in een ander domein), zelfs als deze dataset veel kleiner is! In dit geval kunnen we het model nog steeds finetunen om domeinspecifieke kenmerken te leren herkennen, maar de meest high-level kenmerken zoals randen en hoeken zijn al geleerd door het model. Dit leidt vaak tot bevredigende resultaten in verschillende domeinen, wat hier ook het geval is!
De beeldclassificator die we hebben gekozen voor ons ensemble is het Inception ResNet V2-model, voornamelijk omdat het model gemakkelijk toegankelijk is, een pythonische TensorFlow-implementatie heeft en een state-of-the-art model is. Dit model vereist dat de invoerafbeeldingen een vaste grootte hebben, namelijk dat elke afbeelding 299*299 is in termen van hoogte*breedte. Daarom zijn er beeldvoorbewerkingsstappen genomen om dit mogelijk te maken, aangezien elke afbeelding in onze dataset een variabele grootte had. Elke afbeelding is dus verkleind naar het opgegeven formaat, maar niet door simpelweg de hoogte en breedte aan te passen aan deze afmetingen, omdat dit zou resulteren in een verlies van proportionaliteit voor de meeste afbeeldingen. Om te garanderen dat de hoogte-breedteverhouding behouden blijft, wordt een techniek genaamd padding toegepast. Deze techniek zorgt ervoor dat de beeldverhouding behouden blijft en vult de lege ruimte (in de hoogte of breedte) op met zwarte pixels, wat het vermogen van het neurale netwerk om deze afbeeldingen te classificeren niet beïnvloedt.
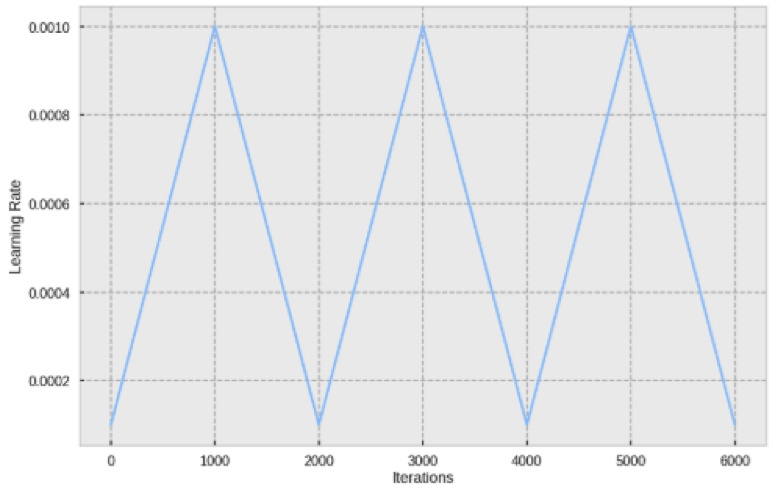
Zodra de afbeeldingen zijn opgevuld en dus in grootte zijn aangepast met behoud van hun beeldverhouding, is het tijd om het model te trainen. Als we transfer learning toepassen, stellen we alleen het bestaande model bij, maar dat betekent niet dat we de parameters moeten laten zoals ze zijn. De belangrijkste parameter van een neuraal netwerk is ongetwijfeld de leersnelheid, die bepaalt hoe goed (en hoe snel) het netwerk naar een optimum convergeert. Er wordt vaak beweerd dat de leersnelheid kan worden bepaald via een trial-and-error benadering, maar hoewel dit niet zo slecht is, bestaan er ook meer ‘gestructureerde’ benaderingen. Een van deze benaderingen is Cyclical Learning Rate (Smith, 2017). Door deze methode toe te passen, kan men optimale grenzen voor de leersnelheid vinden, namelijk een minimale en maximale waarde voor de leersnelheid. Tijdens het trainen van het neurale netwerk zal de leersnelheid tussen deze waarden in bewegen, waardoor vaak sneller goede resultaten worden verkregen dan door alleen een leersnelheidwaarde in te stellen.
In figuur 8 ( Credits ) was de leersnelheid ingesteld om te schommelen tussen een waarde van 0,0001 en 0,0010, terwijl er 6000 iteraties over de gegevens werden uitgevoerd.
Zodra de beeldclassificator is getraind en getest, wordt de validatieset gebruikt om de eigenlijke voorspellingen te genereren. Nogmaals, deze voorspellingen zijn in de vorm van voorspelde waarschijnlijkheden voor elke klasse per product, die zullen worden gebruikt als invoer voor de meta-learner. Laten we nu overgaan naar het laatste deel van het ensemblemodel, de meta-learner.
Meta-leerder
De classifiers op basisniveau, die verantwoordelijk zijn voor de tekst en afbeeldingen, zijn uitgewerkt. Zodra ze hun werk hebben gedaan, wat betekent dat ze voorspelde waarschijnlijkheden hebben gegeven, worden deze waarschijnlijkheden gebruikt als invoer voor de meta-learner. Aangezien de dataset van onze klant uit ongeveer 400 unieke klassen bestond, hebben we nu ongeveer 800 features die als invoer worden gebruikt. Aangezien de meta-learner gewoon een ander classificatiealgoritme is, kiezen we voor deze taak een Support Vector Machine (SVM). De belangrijkste reden is dat een SVM heeft bewezen goed te presteren op classificatietaken waarbij de hoeveelheid kenmerken erg groot is (Joachims, 1998). Dit laat ons achter met een eenvoudige classificatietaak, deze keer het genereren van de werkelijke klassevoorspellingen in plaats van waarschijnlijkheden.
Eindmodel
Eerder in deze blogpost hebben we vermeld dat we verschillende tekstclassificeerders testen om te zien welke combinatie van classificeerders de beste algemene classificatienauwkeurigheid geeft. De reden dat we dit doen is gebaseerd op het ’no free lunch’ theorema, wat betekent dat er simpelweg niet één algoritme is dat over alle algoritmes heerst. Algoritmen reageren verschillend op verschillende datasets en daarom kan het nooit kwaad om verschillende algoritmen uit te proberen. Onze optimale combinatie van classificeerders die ons stapelensemble vormen, wordt hieronder weergegeven.
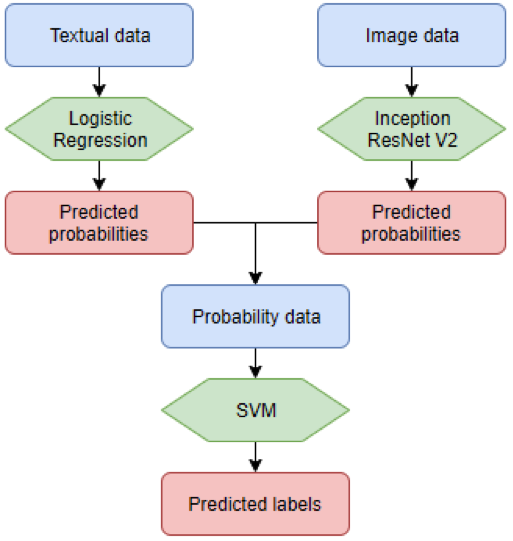
Dit stacking ensemble heeft ons in staat gesteld om tekst- en beeldgegevens van onze klant te combineren, waardoor we onze service hebben kunnen verbeteren en daarmee onze waardepropositie voor deze klant hebben kunnen verhogen! Dit is slechts één voorbeeld van een dienst die wij als Squadra Machine Learning Company aanbieden, aarzel niet om onze andere diensten te bekijken!
Referenties
Džeroski, S., & Ženko, B. (2004). Is combining classifiers with stacking better than selecting the best one?. Machine learning, 54(3), 255-273.
Elberse, A. (2008). Should you invest in the long tail?. Harvard business review, 86(7/8), 88.
Graczyk, M., Lasota, T., Trawiński, B., & Trawiński, K. (2010, March). Comparison of bagging, boosting and stacking ensembles applied to real estate appraisal. In Asian Conference on Intelligent Information and Database Systems (pp. 340-350). Springer, Berlin, Heidelberg.
Joachims, T. (1998, April). Text categorization with support vector machines: Learning with many relevant features. In European conference on machine learning (pp. 137-142). Springer, Berlin, Heidelberg.
Kim, Y. G., Lee, T., Chun, J., & Lee, S. G. (2006). Modified naïve bayes classifier for e-catalog classification. In Data engineering issues in e-commerce and services (pp. 246-257). Springer, Berlin, Heidelberg.
Lahat, D., Adali, T., & Jutten, C. (2014, September). Challenges in multimodal data fusion. In Signal Processing Conference (EUSIPCO), 2014 Proceedings of the 22nd European (pp. 101-105). IEEE.
Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., & Ng, A. Y. (2011). Multimodal deep learning. In Proceedings of the 28th international conference on machine learning (ICML-11) (pp. 689-696).
Rokach, L. (2010). Ensemble-based classifiers. Artificial Intelligence Review, 33(1-2), 1-39.
Smith, L. N. (2017, March). Cyclical learning rates for training neural networks. In Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on (pp. 464-472). IEEE.
Srivastava, N., & Salakhutdinov, R. R. (2012). Multimodal learning with deep boltzmann machines. In Advances in neural information processing systems (pp. 2222-2230).
