Insights
Implementeer Je Machine Learning Model als een REST API op AWS

Dus je hebt dagen, weken of zelfs maanden besteed aan het werken aan je geavanceerde machine learning-model; het opschonen van gegevens, het engineeren van features, het afstemmen van modelparameters en eindeloos testen. En nu het eindelijk klaar is voor productie, wil je het op een eenvoudige en betrouwbare manier beschikbaar maken. Een manier om dit te bereiken is door het te implementeren als een REST API.
Hier bij Machine Learning Company vertrouwen we op Amazon Web Services om onze machine learning-modellen te hosten. Ons automatische productclassificatiemodel is bijvoorbeeld gehost op hun platform. De diensten en functies die Amazon biedt, maken het relatief eenvoudig om grootschalige machine learning-modellen te implementeren vergeleken met enkele jaren geleden. Maar het kan nog steeds een ontmoedigende taak lijken voor iemand die geen ervaring heeft met het AWS-platform of modelimplementatie in het algemeen.
In deze post laat ik je zien hoe je je machine learning-model kunt implementeren als een REST API met behulp van Docker en AWS-diensten zoals ECR, Sagemaker en Lambda. We beginnen met het opslaan van de staat van een getraind machine learning-model, het creëren van inference-code en een lichte server die in een Docker-container kan worden uitgevoerd. Vervolgens implementeren we het gecontaineriseerde model naar ECR en creëren we een machine learning-endpoint in Sagemaker. We sluiten af met het creëren van het REST API-endpoint. Het model dat in deze post wordt gebruikt, is gemaakt met Scikit Learn, maar de hier beschreven aanpak werkt met elk ML-framework waarin de staat van een estimator of transformer kan worden geserialiseerd, bevroren of opgeslagen.
Alle code die in deze post wordt gebruikt, is te vinden in de volgende repository: https://github.com/leongn/model_to_api
Het Model
Voor deze post gebruiken we een sentimentanalysemodel dat is getraind op 100.000 gelabelde tweets (positieve of negatieve sentimenten). Het model neemt een zin of een reeks zinnen als invoer en geeft het voorspelde sentiment voor de overeenkomstige tekst weer. Het bestaat uit twee delen, het eerste deel is Scikit Learn’s TFIDF Vectorizer om de tekst te verwerken, het tweede deel is een Logistic Regression classifier (ook van Sklearn) die verantwoordelijk is voor het voorspellen van het sentiment van een zin.
Het Model Opslaan
De eerste stap in het implementatieproces is om je model voor te bereiden en op te slaan, zodat het gemakkelijk elders kan worden geopend. Dit kan worden bereikt door serialisatie, waarmee de staat van je getrainde classifier wordt bevroren en opgeslagen. Hiervoor gebruiken we Scikit Learn’s Joblib, een serialisatiebibliotheek die specifiek is geoptimaliseerd voor het opslaan van grote numpy-arrays, en dus bijzonder geschikt is voor Scikit Learn-modellen. Als je meer dan één Scikit Learn-estimator of -transformer in je model hebt (bijvoorbeeld een TFIDF-voorprocessor, zoals wij hebben), kun je die ook opslaan met Joblib. Het sentimentanalysemodel omvat twee componenten die we moeten opslaan/bevriezen: de TFIDF-tekstvoorprocessor en de classifier. De volgende code dumpt de classifier en tfidf vectorizer naar de map Model_Artifacts.
from sklearn.externals import joblib
joblib.dump(classifier, 'Model_Artifacts/classifier.pkl')
joblib.dump(tfidf_vectorizer, 'Model_Artifacts/tfidf_vectorizer.pkl')Er zijn geen limieten aan de grootte en het aantal modelcomponenten. Als het model een groter dan gebruikelijke geheugencapaciteit of meer rekenkracht vereist, kun je eenvoudig een krachtigere AWS-instantie kiezen.
Het Maken van de Dockerfile
Zodra de estimators en transformer zijn geserialiseerd, kunnen we een Docker-image maken dat onze inference- en serveromgeving bevat. Docker maakt het mogelijk om je lokale omgeving te verpakken en op elke andere server/omgeving/computer te gebruiken zonder je zorgen te hoeven maken over technische details. Je kunt hier meer leren over Docker Images en Containers en hoe je deze definieert via de Docker-documentatie. Het Docker-image bevat alle noodzakelijke componenten die je model in staat stellen om voorspellingen te doen en te communiceren met de buitenwereld. We kunnen een Docker-image definiëren met een Dockerfile die de inhoud van de omgeving specificeert: we willen Python 3 installeren, Nginx voor de webserver en verschillende Python-pakketten zoals Scikit-Learn, Flask en Pandas.
De Dockerfile is te vinden in de map container: Dockerfile
Het eerste deel van de Dockerfile zal een reeks Linux-pakketten installeren die nodig zijn om een server te draaien en onze Python-code uit te voeren, het tweede deel definieert een set Python-pakketten die we nodig zullen hebben (zoals Pandas en Flask) en deel drie definieert de omgevingsvariabelen. Het laatste deel van het bestand vertelt Docker welke map ( sentiment_analysis ) onze inference- en servercode bevat die aan het image moet worden toegevoegd.
Het Definiëren van de Server- en Inference-code
We kunnen nu beginnen met het maken van de code die je machine learning-model zal bedienen vanuit de Docker-container. We gaan het Flask-microframework gebruiken dat inkomende verzoeken van buitenaf afhandelt en de voorspellingen van je model retourneert. Dit bevindt zich in de map container/sentiment_analysis in het predictor.py bestand.
Het eerste deel van het bestand importeert alle noodzakelijke afhankelijkheden (elke afhankelijkheid die hier wordt gebruikt, moet ook worden toegevoegd in het tweede deel van de Dockerfile). We laden de geserialiseerde modelcomponenten met Joblib. Vervolgens maken we de Flask-app die onze voorspellingen zal serveren. De eerste route (Ping) controleert de gezondheid van de container door te controleren of de classifier-variabele bestaat. Als deze niet bestaat, retourneert het een fout. Deze ‘ping’ wordt later door Sagemaker gebruikt om te controleren of de server draait en gezond is.
Dan komt het voorspellingsgedeelte: de server accepteert POST-verzoeken met JSON-gegevens in het volgende formaat:
{"input":
[
{"text" : "Input text 1"},
{"text" : "Input text 2"},
{"text": "Input text 3"}
]
}Eerst transformeren we de JSON-gegevens naar een Pandas DataFrame, vervolgens transformeren we de zinnen in de DataFrame met de TFIDF-vectorizer en maken we voorspellingen met onze classifier. De classifier geeft 0 (negatief sentiment) en 1 (positief sentiment) als output. We zullen de 0 en 1 respectievelijk veranderen in Negatief en Positief voor de leesbaarheid. Tot slot transformeren we de resultaten terug naar JSON, die als antwoord op het verzoek kan worden verzonden.
Configureren van de Webserver
De meeste mensen kunnen dit deel overslaan, omdat ze het aantal workers dat hun server gebruikt niet hoeven te wijzigen. Maar in het geval dat je model groot is (bijvoorbeeld minstens 2GB), wil je misschien de parameter model_server_workers in het configuratiebestand wijzigen. Deze parameter bepaalt hoeveel instanties van de Gunicorn-server parallel worden gestart. De standaardwaarde gebruikt het totale aantal CPU’s op het systeem als het aantal workers. Elk van deze workers zal een kopie van het model en de inference code bevatten, dus als je een groot model hebt, kan het geheugen van je machine/instance/server snel vol raken. Daarom wil je misschien het aantal workers handmatig instellen. Voor een groot model stel je het in op 1 en voer je wat tests uit om te zien hoe hoog je kunt gaan. Deze parameter kan worden gedefinieerd via omgevingsvariabelen.
Het Bouwen van de Docker Image
Nu we klaar zijn met het definiëren van de omgeving, de inference code en de server, kunnen we verder gaan met het bouwen van onze Docker-image voor testen.
Verplaats je terminal naar de map waar de Dockerfile-bestand zich bevindt. Voer vervolgens het volgende commando uit om je image te bouwen met de naam prediction_docker_image:
docker build -t prediction_docker_image .Let op de punt aan het einde van het commando, hiermee vertelt Docker om te zoeken naar het Dockerfile-bestand in de huidige directory. Als je een machtigingsfout krijgt, voeg dan sudo toe vóór het commando. Docker zal nu beginnen met het bouwen van de image en zal deze toevoegen aan de huidige image repository op je systeem.
Het Starten van een Docker-container
Nu de Docker-image gebouwd is, willen we deze uitvoeren en testen. Maar eerst moeten we alle geserialiseerde modelonderdelen en eventuele andere extra bestanden die je gebruikt naar de map verplaatsen. De map heeft dezelfde mappenstructuur als Sagemaker zal gebruiken op de AWS-instantie.
Vervolgens zullen we de image en server starten met het script serve_local.sh , dat de Docker-image vertelt waar de testgegevens zich bevinden, op welke poorten deze moet werken (8080) en wat de naam is van de Docker-image die de inference code bevat. Ga naar de map met je terminal en voer het volgende commando uit om de Docker-container en de server aan boord te starten:
./serve_local.sh prediction_docker_imageDe container wordt gestart, de server wordt opgestart en je zult het volgende bericht zien (het aantal workers is afhankelijk van de parameter model_server_workers):

Als je de geheugen- en CPU-gebruik van je Docker-container wilt controleren, open dan een nieuwe terminal en voer het volgende commando uit:
docker statsPerforming Test Inferences
Nu de server draait, kunnen we wat gegevens naar de server sturen om te testen. Dit kan worden gedaan met het predict.sh script. Dit script stuurt een JSON-bestand naar de server.
Terwijl je nog steeds in de map met je terminal bent, typ je het volgende commando:
./predict.sh input.jsonAls alles vlot verloopt, zou je een aantal voorspellingen moeten terugkrijgen. Gefeliciteerd, je Docker image is klaar voor implementatie!
Het Docker Image Implementeren
De docker image en de machine learning model artefacten worden apart gehouden in Sagemaker. Op deze manier kun je een Docker image bestand maken met je inferentiecode, maar er verschillende versies van je model in stoppen. We beginnen met het vers aangemaakte Docker image te pushen naar Amazon Elastic Container Registry (ECR) waar ons image wordt opgeslagen. Om dit te laten werken, moet je de AWS CLI geïnstalleerd hebben en een bestaand AWS account geconfigureerd hebben op je systeem. Als je je AWS-configuratie wilt controleren, voer dan het volgende commando uit in je terminal:
aws configure listAls er nog geen configuratie aanwezig is, kun je er eenvoudig een maken met het commando aws configure en je AWS-inloggegevens invoeren. Het is belangrijk om op te merken dat je je regio zorgvuldig moet kiezen; alle modelcomponenten moeten zich in dezelfde regio bevinden om te kunnen communiceren.
Het push-proces kan worden uitgevoerd met behulp van het script build_and_push.sh in de map `container`. Dit script zal automatisch een nieuwe ECR-repository maken, als deze nog niet bestaat, en je image ernaar pushen. Verplaats je terminal naar de map en voer het volgende uit:
./build_and_push.sh prediction_docker_imageZodra de image is geüpload, open je de AWS-console op https://console.aws.amazon.com en ga je naar ECR en klik je in het linker paneel op `Repositories`. Selecteer vervolgens de image die je zojuist hebt geüpload en kopieer de Repository URI bovenaan de pagina (het kan handig zijn om een tijdelijk tekstbestand aan te maken om deze informatie op te slaan, aangezien we deze later in het proces nodig zullen hebben).
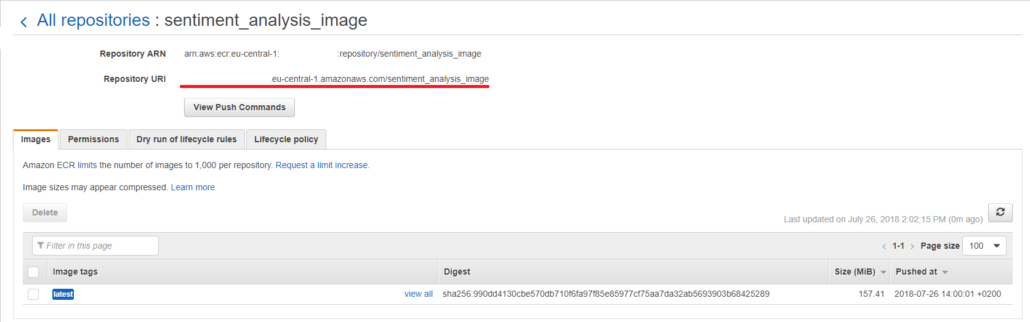
Modelartefacten Uploaden naar S3
Zoals eerder besproken, bevat de Docker-image alleen de inferentieomgeving en -code, niet het getrainde geserialiseerde model. De geserialiseerde getrainde modelfiles, modelartefacten genoemd in Sagemaker, worden opgeslagen in een aparte S3-bucket. We beginnen met het plaatsen van alle benodigde (geserialiseerde) modelcomponenten in een tar.gz-gecomprimeerd bestand ( here te vinden). Je kunt deze vervolgens uploaden naar een van je bestaande S3-buckets (in dezelfde regio als je ECR-image), of een nieuwe maken. Deze stappen kunnen worden uitgevoerd met de AWS CLI of via de online interface.
Om een nieuwe bucket te maken met de AWS online interface, ga je naar de
AWS console
en selecteer je S3. Klik vervolgens op Create Bucket, kies een naam voor de bucket (bijvoorbeeld: sentiment-analysis-artifacts) en de regio waarin je wilt dat je bucket zich bevindt.
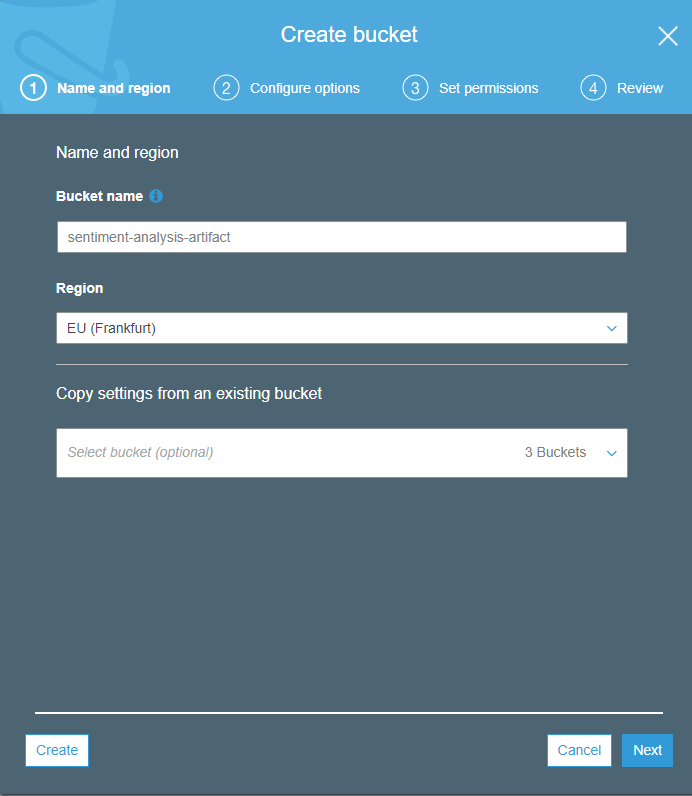
De regio moet dezelfde zijn als de regio die je hebt gebruikt voor ECR. Op de volgende pagina Configure options kun je verschillende instellingen met betrekking tot je bucket wijzigen. Ik raad aan om automatische versleuteling te selecteren. Het derde scherm heeft betrekking op het instellen van toegangsrechten. De standaardinstellingen zijn geschikt voor de meeste gebruikers. Tot slot kun je op de laatste pagina al je instellingen controleren.
Nadat je bucket is aangemaakt, open je de bucket door erop te klikken en selecteer je ‘Upload’. Ga verder door het gecomprimeerde bestand met je modelartefacten te selecteren. Voor de volgende stappen zijn de standaardinstellingen geschikt. Wacht tot de upload is voltooid, klik op het nieuw geüploade bestand en kopieer de URL onderaan de pagina voor later gebruik.
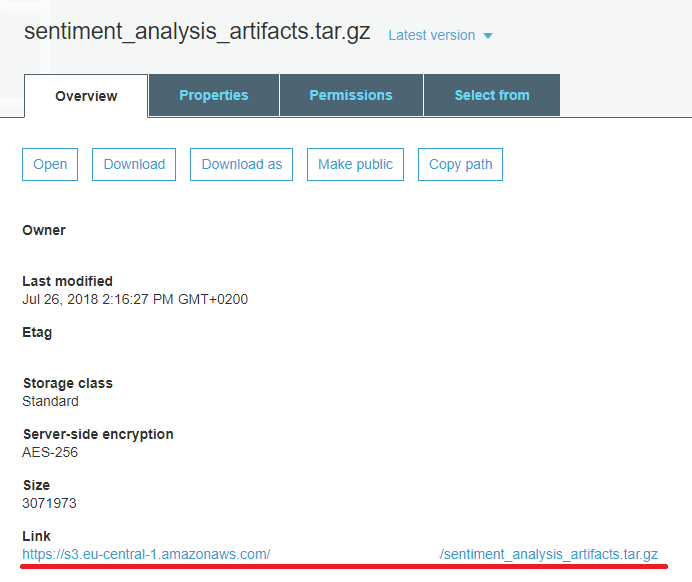
De Afbeelding Instellen in Sagemaker
Modelaanmaak
Nu de afbeelding is gedeployed naar ECR en de machine learning modelartefacten zijn geüpload naar S3, kunnen we beginnen met het configureren van de Sagemaker-voorspellingsendpoint. We moeten beginnen met het aanmaken van een Sagemaker-modelresource. Ga naar Sagemaker via je AWS-console, klik in het linker paneel onder Inference op Models, en klik vervolgens aan de rechterkant van het scherm op Create Model (zorg ervoor dat je nog steeds in de juiste regio bent). Eerst moeten we ons model een naam geven en een IAM-rol toewijzen. Als je al een IAM-rol voor Sagemaker hebt, kies dan die. Anders kies je Create Role uit het dropdownmenu. We willen ons Sagemaker-model toegang geven tot onze S3-bucket. Geef de naam van je S3-bucket (sentiment-analysis-artifacts) op onder Specific S3 buckets of selecteer Any S3 bucket.
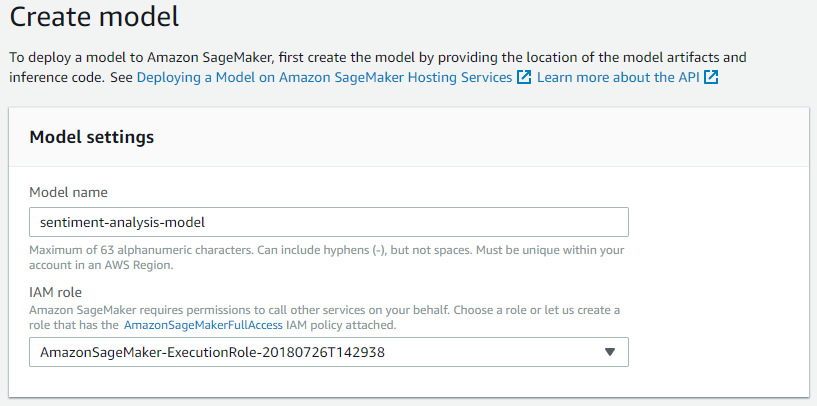
We moeten Sagemaker vertellen waar de Docker-afbeelding en modelartefacten zich bevinden. Je kunt nu de ECR URI en S3 URL die we in de vorige stappen hebben verkregen in de overeenkomstige velden plakken. Voeg de tag `latest` toe aan het einde van je afbeelding-URI (bijvoorbeeld: **********.ecr.eu-central-1.amazonaws.com/sentiment_analysis_image:latest) om ervoor te zorgen dat Sagemaker altijd de laatste versie van je model uit ECR haalt. De container host naam is optioneel en het toevoegen van tags zoals Version — 1.0 kan nuttig zijn voor versiebeheer. Rond af door op “Create model” te klikken.
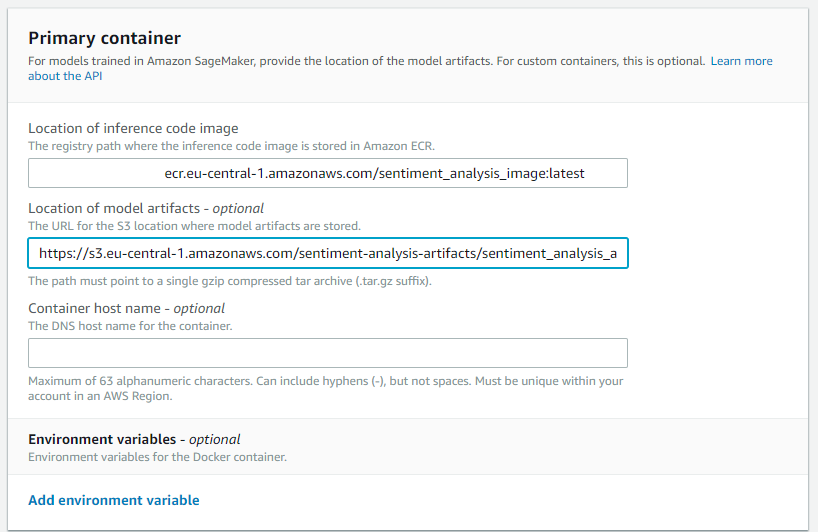
Endpointconfiguratie
De volgende stap is om een endpointconfiguratie te maken in Sagemaker (left pane -> Endpoint Configurations-> Create endpoint configuration). Hiermee kunnen we specificeren welk model aan het endpoint zal worden toegevoegd en op welke AWS-instantie het moet worden uitgevoerd. Begin met het geven van een naam (bijv. sentiment-analysis-endpoint-configuration). Klik vervolgens op Model toevoegen en selecteer het eerder gemaakte model.
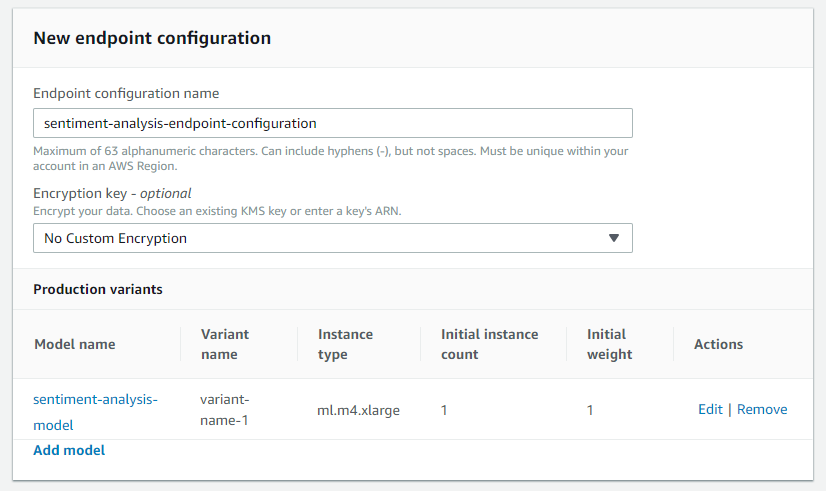
We kunnen het model vervolgens bewerken door op de knop Bewerken ernaast te klikken om te kiezen op welke AWS-instantie het moet worden uitgevoerd. De standaard ml.m4.large zou voldoende moeten zijn voor de meeste belastingen, maar als je model relatief klein of groot is, rekenintensief of lichtgewicht, kun je een andere kiezen (zie de soorten beschikbare exemplaren en de prijzen per regio ) . Rond deze stap af door op Maak endpointconfiguratie te klikken.
Endpointcreatie
De laatste stap bestaat uit het creëren van het Sagemaker-endpoint (left-pane-> Endpoints-> Create endpoint). Begin met het geven van een naam aan het endpoint, deze naam zal later door je API-gateway worden gebruikt om het endpoint aan te roepen. Selecteer vervolgens de in de vorige stap gemaakte endpointconfiguratie en klik op Selecteer endpointconfiguratie.
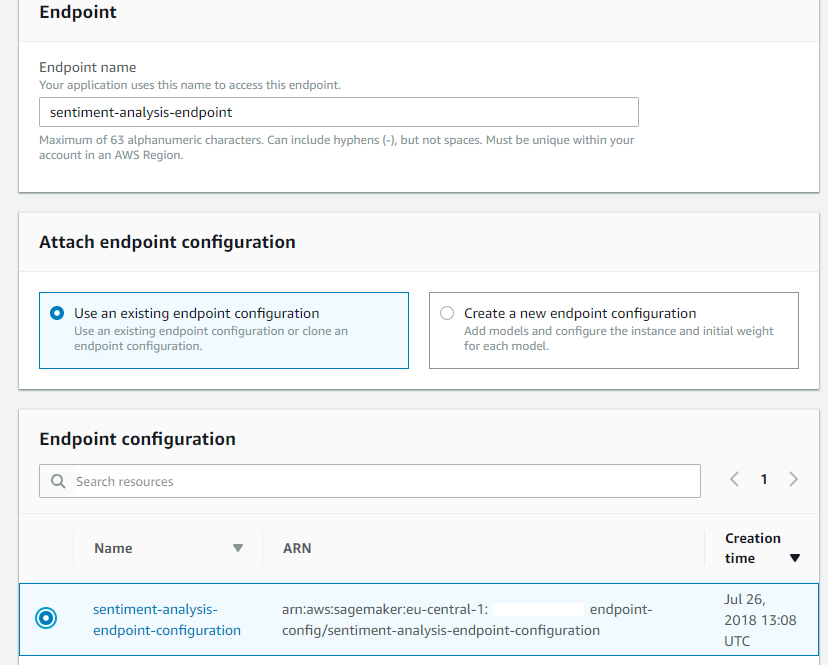
Rond het proces af door op Maak endpoint te klikken. Sagemaker zal vervolgens beginnen met het implementeren van je model, dit kan even duren.
Als alles volgens plan verloopt, zie je InService verschijnen in de Statuskolom.
Het Maken van de REST API
Zodra het Sagemaker-endpoint is aangemaakt, kun je vanuit je AWS-account toegang krijgen tot het model met behulp van de AWS CLI of bijvoorbeeld de AWS Python SDK (Boto3). Dit is prima als je wat interne tests wilt uitvoeren, maar we willen het beschikbaar maken voor de buitenwereld, dus we zullen een API moeten maken.
Dit kan eenvoudig worden bereikt met behulp van Amazon’s Chalice bibliotheek . Het is een microframework dat snelle creatie en implementatie van apps op AWS Lambda mogelijk maakt en de creatie van een API vereenvoudigt.
Allereerst moet je Chalice en de AWS SDK voor Python installeren met het volgende commando:
sudo pip install chalice boto3De API-gateway moet worden ingezet in dezelfde regio als je model-endpoint. Om er zeker van te zijn dat dit correct is, kun je je regioconfiguratie opnieuw controleren door het volgende commando in je terminal in te voeren:
aws configure listAls de regio onjuist is, configureer deze dan correct met:
aws configureDe code voor dit onderdeel is te vinden in de map api_creation .
Het app.py bestand in de hoofdmap bevat de routeringslogica van de API: welke acties zullen worden uitgevoerd bij het ontvangen van bepaalde verzoeken (zoals POST). Hier kun je eventueel het formaat van de inkomende gegevens wijzigen of extra controles uitvoeren als deze niet worden uitgevoerd in de inferentiecode die aanwezig is in je Docker-container. De belangrijkste functie van deze code is om je Sagemaker-endpoint aan te roepen wanneer een POST-verzoek met gegevens naar je API wordt gestuurd, en om het antwoord terug te geven.
Als alles is geconfigureerd, kun je de API-gateway implementeren door naar de api_creation map te gaan met je terminal en het volgende commando uit te voeren:
chalice deployChalice zal dan de URL van de REST API retourneren. Kopieer deze en sla deze op.
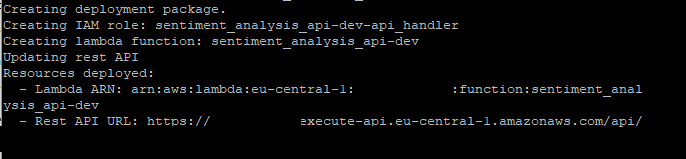
Je kunt nu die eindpunt-URL gebruiken om verzoeken uit te voeren. Je kunt de volgende Python-code gebruiken om dit te testen:
import requests
# Define test JSON
input_sentiment = {'input': [{'text' : 'Today was a great day!'}, {'text' : 'Happy with the end result!'}, {'text': 'Terrible service and crowded. Would not' ]}
input_json = json.dumps(input_sentiment)
# Define your api URL here
api_url = 'https://*******.execute-api.eu-central-1.amazonaws.com/api/'
res = requests.post(api_url, json=input_json)
output_api = res.text print(output_api)De bovenstaande code leverde de volgende uitvoer op:
{“output”:
[
{“label”: “Positive”},
{“label”: “Positive”},
{“label”: “Negative”}
]
}Ziet er consistent uit met de invoer, je machine learning API is nu volledig operationeel!
Endpoint Uitschakelen
Als je klaar bent en de API niet meer nodig hebt, vergeet dan niet om het endpoint in Sagemaker te verwijderen omdat de kosten anders blijven doorlopen.
Conclusie
In deze post heb je gezien hoe je:
- Je machine learning modelcomponenten serializeert voor implementatie
- Je eigen Docker image maakt met inference en server code
- Je Docker image naar ECR pusht
- Je modelartefacten opslaat naar S3
- Een Sagemaker endpoint configureert en maakt
- Een API endpoint maakt met Chalice
