Insights
Hoe Je Automatisch Productbeschrijvingen Kunt Creëren Met NLP
De afgelopen jaren is het aantal online consumenten aanzienlijk toegenomen. Voor e-commercebedrijven is het essentieel om zo hoog mogelijk in zoekmachines te ranken om potentiële klanten naar hun website te leiden. Het toepassen van Search Engine Optimization (SEO) kan een effectieve strategie zijn om de zichtbaarheid van een website te verbeteren. Identieke of dubbele productbeschrijvingen kunnen de positie in zoekmachines verlagen. Bovendien dienen beschrijvingen informatief, realistisch en in begrijpelijke taal geschreven te zijn om de productzichtbaarheid te vergroten.
Technieken voor Natural Language Processing (NLP) kunnen het proces van het schrijven van productbeschrijvingen versnellen. In dit artikel gebruiken we de Transformer, die voor het eerst werd geïntroduceerd door Vaswani et al. (2017) en waar we later in dit artikel meer details over zullen geven. We hebben de transformer-architectuur specifiek getraind voor de Nederlandse taal en beschrijven de mogelijkheid om productbeschrijvingen te automatiseren. Het doel is om productattributen om te zetten in een correcte en unieke Nederlandse beschrijving. Dit houdt in dat input een productkenmerk is, zoals een wascapaciteit van 8 kg voor een wasmachine, en dat de output een correcte en unieke Nederlandse zin is.
Tot nu toe waren de meeste onderzoeken gericht op de Chinese taal; in dit artikel zullen we uitleggen hoe je Nederlandse beschrijvingen kunt genereren. Wij zijn geïnspireerd door Chen et al. (2017), die de Knowledge Personalized (KOBE) productbeschrijvingsgenerator hebben ontwikkeld met behulp van de transformer-architectuur.
Transformator
Vaswani et al. (2017) hebben het NLG-veld revolutionair veranderd door een nieuwe, vereenvoudigde netwerkarchitectuur voor te stellen in hun paper ‘Attention is all you need’, genaamd de Transformer. Dit basismodel behaalt al betere prestaties dan de state-of-the-art BLEU-scores in diverse NLG-taken. Bovendien vereist de Transformer minder trainingstijd dan traditionele modellen. Huidige sequentiemodelleringsarchitecturen zijn vaak gebaseerd op recurrente of convolutionele neurale netwerken en gebruiken een attentie-mechanisme om de encoder en decoder te verbinden. De Transformer daarentegen vertrouwt uitsluitend op attentie-mechanismen. Dit betekent dat het Transformer-model een zelf-attentie encoder-decoder-architectuur hanteert. Diverse studies hebben deze architectuur succesvol geïmplementeerd en veelbelovende resultaten geboekt. De transformer-architectuur wordt geïllustreerd in de bijgevoegde figuur.
De dataset die we gebruikten bevat ongeveer 230.000 zinnen verdeeld over 52 verschillende productgroepen, allen binnen de elektronica. Elk product heeft een specifieke set productattributen. In combinatie met deze lijst konden we de attributen uit de beschrijvingen extraheren, welke in het Nederlands waren opgesteld. Dit vormt echter een nadeel, aangezien de dataset beperkt is. Hoewel 230.000 zinnen veel lijkt, hebben machine learning-modellen vaak veel meer data nodig. Bovendien zijn de zinnen verspreid over ongeveer 50 productcategorieën en bevatten niet alle zinnen een productattribuut (slechts 75.000 zinnen bevatten er minimaal één). Aangezien we ons richten op het vertalen van attributen naar Nederlandse zinnen, waren we hierdoor beperkt in het aantal bruikbare zinnen. Om ook de overige zinnen te kunnen benutten, maakten we gebruik van de Term Frequency Independent Document Frequency (TF-IDF) methode om de twee meest unieke woorden uit elke zin te extraheren. Een woord wordt als uniek beschouwd als het niet frequent voorkomt in de hele dataset.
De woorden in de input hebben een aanzienlijke invloed op de output. In deze blog bespreken we verschillende varianten en geven we aan wat effectief is en wat niet. De output bestaat altijd uit afzonderlijke zinnen; het genereren van langere beschrijvingen is (nog) niet gelukt. Tijdens het trainingsproces werd multi-bleu als evaluatiemetric gebruikt, een gangbare methode in tekstgeneratie-opdrachten. We evalueerden de gegenereerde zinnen voornamelijk op hun uniciteit. Het bleek dat veel zinnen letterlijk uit de trainingsset waren gekopieerd, wat niet de bedoeling is, aangezien we unieke zinnen willen creëren. Deze uniciteitspercentage geeft aan welk deel van de geproduceerde zinnen niet letterlijk uit de trainingsset afkomstig is.
Het experiment met de hoogste uniciteitsscore was degene waarin we alle data gebruikten en de productcategorie, evenals de 2 TF-IDF-woorden (de twee meest unieke woorden uit een zin), als input toepasten. Na de training behaalde het model een uniciteitspercentage van ongeveer 70%. Het doel van deze methode was vooral om productattributen te extraheren, maar in de praktijk werden deze niet als unieke woorden gezien. Omdat we geïnteresseerd zijn in de vertaling van deze attributen naar beschrijvingen, bleek deze configuratie niet optimaal. Toch is aangetoond dat dit model in staat is om unieke zinnen te genereren.
Bij het tweede experiment gebruikten we de productcategorie samen met de productattributen als input. Voor dit experiment hadden we minder data beschikbaar, omdat we alleen zinnen konden meerekenen die een attribuut beschrijven. In ongeveer 10% van de gevallen genereerde het model unieke zinnen. Hieronder zijn enkele door het model gegenereerde zinnen weergegeven (in het Nederlands):
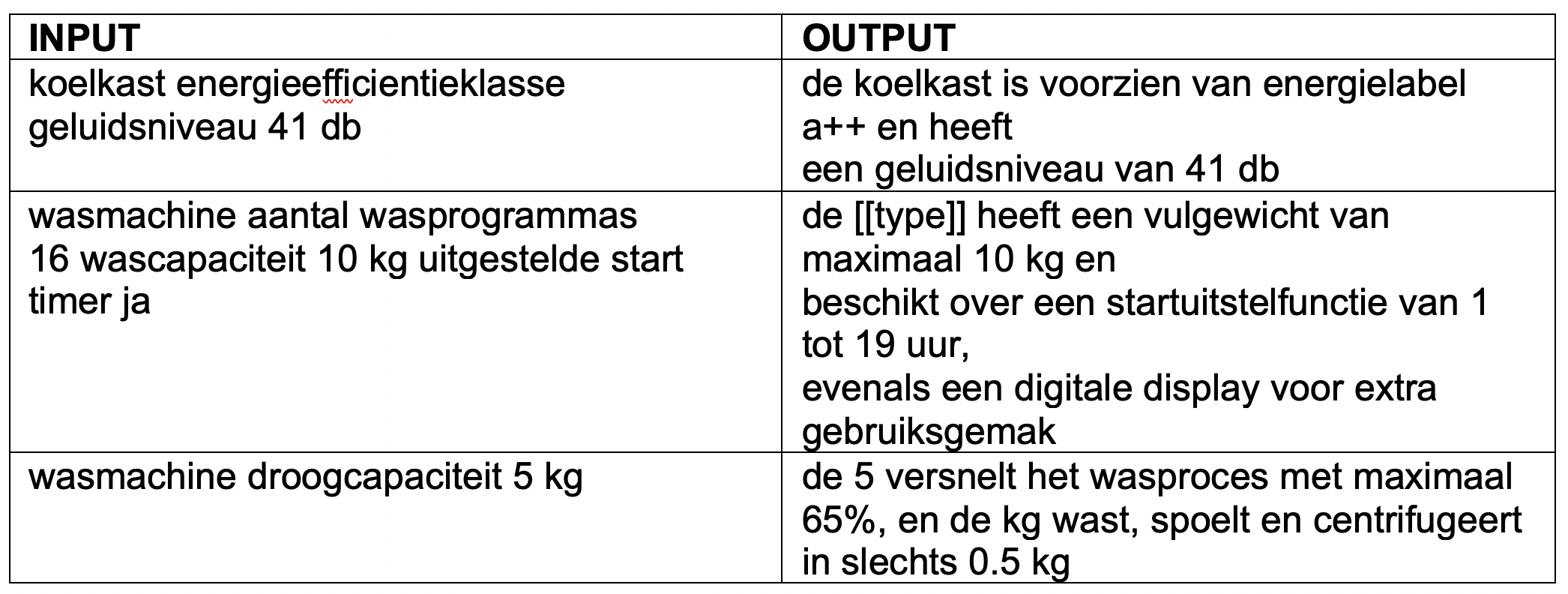
In deze blog hebben we onderzocht of het mogelijk is om productbeschrijvingen te genereren. Het is gebleken dat dit haalbaar is in het Nederlands, maar dat verdere optimalisatie van de modellen nodig is. Een beperking van de Nederlandse taal is dat er weinig tekstuele data beschikbaar is, terwijl machine learning-modellen vaak veel gegevens vereisen. Ook komt het voor dat de inputzin (de attributen) letterlijk in de outputzin wordt gebruikt. Dit is niet problematisch voor veel attributen, maar de attributen “hoogte verstelbaar” en “hoogte 24 cm” bevatten beide het overlappende woord “hoogte”, wat verkeerd geïnterpreteerd kan worden. In 25% van de gevallen verschijnt de naam van de productcategorie (uit de input) letterlijk in de gegenereerde zin, wat vergelijkbaar is met de zinnen uit de dataset.
Samenvattend is het mogelijk om Nederlandse productbeschrijvingen te genereren met een transformer-architectuur. Hoewel slechts een klein percentage van de geproduceerde beschrijvingen als uniek werd beschouwd, genereerde het model wel unieke beschrijvingen. Onze focus ligt op het omzetten van productattributen naar beschrijvingen. Hiervan was ongeveer 10% uniek en de gegenereerde beschrijvingen bevatten de opgegeven attributen, geschreven in correct Nederlands.
