Insights
De Complexe Uitdagingen van Data Syndicatie

Het Belang van Productinformatie
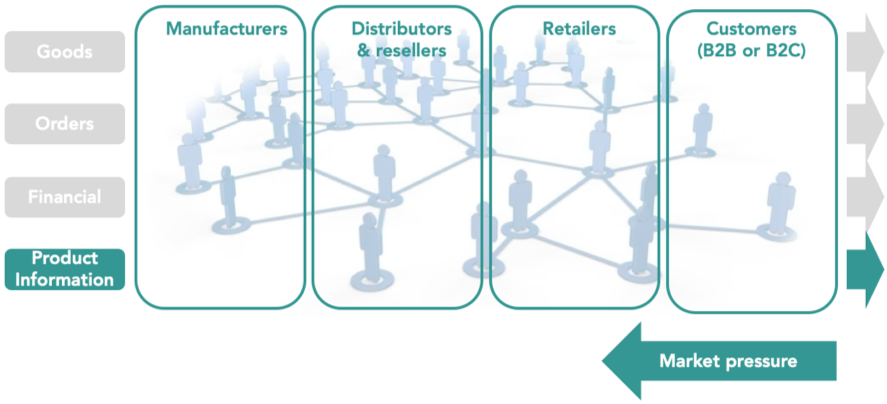
In het verleden was er veel aandacht voor de fysieke productstroom en uitwisseling van order- en factuur gerelateerde informatie tussen partijen in de waardeketen. De volgende vragen werden hier mee beantwoord: Hoe komt een product van de fabrikant naar het magazijn van de distributeur? Hoe wordt het product vanuit het magazijn naar de detailhandelaar verzonden? Of hoe kunnen een distributeur en detailhandelaar hun administratieve processen optimaliseren door verkoop- en inkooporders digitaal uit te wisselen? Met andere woorden, de focus lag op data die valt onder Enterprise Resource Planning (ERP), inclusief data over logistiek, verkoop en orderadministratie. In het onderstaande overzicht staan de grijze stromen voor deze activiteiten. Dit ERP-gerelateerde domein is de afgelopen decennia relatief volwassen geworden, maar we zien bedrijven nog steeds worstelen met bijvoorbeeld EDI-gebaseerde Order To Cash-processen.
Er was echter onvoldoende aandacht voor de groene stroom van het onderstaande overzicht, die staat voor een efficiënte uitwisseling van gestructureerde productdata. Vooral door een aanzienlijke groei van eCommerce en eBusiness werd deze stroom van vitaal belang voor de moderne bedrijfsvoering. Omdat klanten goed geïnformeerd willen worden over hun online aankoop, moeten winkeliers veel productinformatie op de website verstrekken. De drang om vertrouwde en rijke productdata te hebben komt dus altijd van de rechterkant van de waardeketen, zoals blijkt uit onderstaand overzicht. Retailers hebben deze productdata echter niet zelf, dus moeten ze navraag doen bij de distributeur of reseller. De distributeur heeft zijn productdata echter ook niet, dus moet hij contact opnemen met de fabrikant.
Wat is Data Syndicatie?
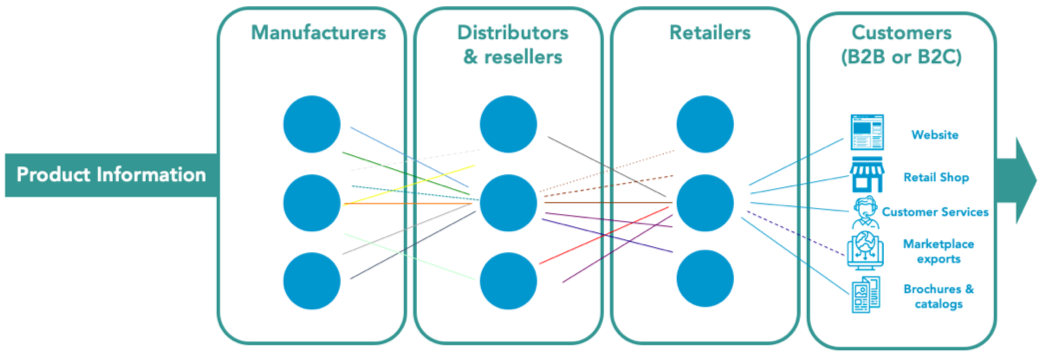
Het onderstaande overzicht visualiseert de uitdagingen op het gebied van productdata voor zakenpartners binnen de waardeketen. Verschillende organisaties verzamelen en bewaren hun data op hun eigen manier, aangezien elk van hen zijn eigen datamodel heeft en als zodanig communiceert, in ieders eigen data-taal. Daarom is efficiënte Data Syndicatie nodig. Kort gezegd is Data Syndicatie de synchronisatie of syndicatie van gegevens tussen organisaties of systemen die verschillende data-talen spreken. Squadra onderzoek bevestigt dat dit een van de grootste uitdagingen is bij het implementeren van Product Information Management (PIM) of Product MDM (Master Data Management).
Hoe Werkt Het?
Sommige organisaties proberen data te syndiceren door de inkomende bestanden simpelweg te vergelijken met hun eigen datamodel, en de data met de hand te ‘vertalen’. Maar stel je voor dat je dit moet doen voor een retailer die honderden of misschien zelfs duizenden verschillende productgroepen verkoopt, afkomstig van honderden verschillende leveranciers, die allemaal hun eigen dataconventie hebben. Dat is gewoon niet intelligent en ongelooflijk tijdrovend.
Om efficiënter te kunnen werken, werken sommige organisaties met datapools. Data pools zijn organisaties die grote hoeveelheden data verzamelen, en maken het mogelijk voor partijen, vaak distributeurs, groothandels en retailers, om deze data van vele leveranciers in een uniform formaat te verkrijgen.
Een andere manier waarop organisaties efficiënter kunnen werken, is door gebruik te maken van datastandaarden. Zoals eerder vermeld, spreken alle organisaties verschillende data-talen, en er is behoefte aan een soort Lingua Franca. Datastandaarden, zoals GS1, ETIM en ecl@ss, definiëren regels voor datarecords. Zo beslist de GS1 normalisatiecommissie over de uniforme naam van het attribuut kleur buitenkussen en dat voor kleur buitenkussen de attribuutwaarde alleen geel, blauw of rood mag bevatten. Door deze standaarden toe te voegen, hebben organisaties opties voor data invoer gedefinieerd, waardoor een gemeenschappelijke data-taal ontstaat.
Hoe Kan Je Uniek Zijn, Ook Bij Gebruik van een Standaard?
Stel je voor dat je een website hebt die schoenen verkoopt. Om klanten te helpen bij het vinden van de perfecte schoenen, kunnen veel kenmerken van een product worden gestandaardiseerd, zoals de maat, het materiaal en de kleur van een schoen. Andere informatie op uw website, zoals marketingteksten, moet echter uniek zijn om uw organisatie te onderscheiden van uw concurrenten. Jos Schreurs , oprichter-partner van Squadra: “Marketingteksten, de productnaam en bij voorkeur metadata van afbeeldingen op de website moeten uniek zijn, want dat is waar zoekmachines zoals Google de voorkeur aan geven (SEO). Alle standaardkenmerken van een product kunnen worden gestandaardiseerd, en aanvullende informatie zoals de marketingteksten is de unieke branding saus die je over je gestandaardiseerde productkenmerken giet om uniek te zijn”.
De Rol van Product Informatie Management (PIM)-systemen
In een PIM-systeem kan een organisatie alle relevante productinformatie beheren en organiseren. PIM-systemen hebben vaak een Vendor Portal en sommige bevatten zelfs slimme datasheets. Dit zijn spreadsheets waarin toezicht op het invoeren van data is opgenomen. Als in de spreadsheet bijvoorbeeld de kleuropties geel, blauw en rood zijn, en de leverancier wil groen invullen, dan staat de slimme datasheet dit niet toe. Dit is echter geen oplossing voor de uitdaging van verschillende datatalen, aangezien nog steeds een van de partijen de data handmatig naar het juiste formaat moet omzetten. “Helaas zien we dat de meeste PIM-leveranciers oude technieken gebruiken, zoals business rules en attribute to attribute mapping om data te transformeren. Meer innovatieve tooling is echter in staat om sets van relatief slechte data om te zetten in een uniforme data-taal met behulp van AI en Machine Learning-technologie. Sommige PIM-tools zijn onlangs begonnen met Machine Learning, maar meestal is dit nog steeds erg basic. “Deze nieuwe technologieën vereenvoudigen de uitdagingen van Data Syndication en Squadra heeft deze technologieën omarmd met de
Squadra Machine Learning Company
. Door het ontbreken van bovengenoemde functionaliteit heeft Squadra MLC een set tools ontwikkeld die als add-on bovenop een PIM-systeem kunnen worden gebruikt. Deze PowerSuite kan stand-alone worden gebruikt (bijv. om SEO-tekst te maken) maar ook via API’s worden verbonden met een PIM-systeem (bijv. om op Machine Learning gebaseerde classificatie en transformatie te vergemakkelijken).
De Rol van Squadra Master Data Management
Squadra MDM is een op kennis gebaseerde en oplossingsgerichte organisatie gespecialiseerd in Product Informatie Management en Master Data Management. Squadra ondersteunt klanten bij MDM-uitdagingen, waaronder meestal Data Syndication. Voorbeelden van organisaties die Squadra MDM ondersteunde met hun Data Syndication-uitdagingen zijn Rituals, Kruidvat, De Mandemakers Group, Sonepar (moeder Technische Unie) en Wehkamp.
Detailhandelaren kopen producten van fabrikanten waarvoor ze data nodig hebben en verkopen deze op hun website of mogelijk via andere marktplaatsen, waarvoor ze data moeten verstrekken. “Dit vat de twee kanten van Data Syndication samen: het verzamelen en verstrekken van data. Datasyndicatie is in wezen het hergebruiken van data, inclusief de transformatie van data om ze opnieuw te gebruiken op verschillende platformen, media of systemen”, besluit Marc Koetsier, MDM associate bij Squadra.
