Insights
Convolutionele Neurale Netwerken voor Tekstclassificatie met Risicobeoordeling

Onze stagiair Maurizio Sluijmers heeft onlangs zijn master in Econometrics and Mathematical Economics aan de Universiteit van Tilburg afgerond. Voor zijn afstudeerscriptie heeft Maurizio onderzoek gedaan naar het gebruik van Convolutionele Neurale Netwerken voor Tekstclassificatie in combinatie met Risicobeoordeling. In deze blogpost wordt zijn scriptie kort samengevat, en deelt hij enkele van zijn bevindingen en inzichten over het onderwerp.
Introductie tot Tekstclassificatie en Risicobeoordelingen
Natural Language Processing (NLP) is altijd een belangrijk onderdeel geweest van onderzoek in de kunstmatige intelligentie (AI). Het belangrijkste doel van NLP is het op een zinvolle manier interpreteren en begrijpen van menselijke talen. Tekstclassificatie is een van de meest geavanceerde onderdelen van NLP. Het doel van tekstclassificatie is om tekstuele data efficiënt te categoriseren in één of meerdere vooraf gedefinieerde categorieën. Tekstclassificeerders hebben bewezen een kosteneffectieve en snelle manier te zijn om tekstuele gegevens te structureren. Er zijn zowel traditionele methoden (zoals Logistische Regressie en Support Vector Machines) als geavanceerdere deep learning technieken zoals Convolutional Neural Networks (CNN) en Recurrent Neural Networks beschikbaar voor deze taak. De potentie van deep learning in tekstclassificatie werd voor het eerst aangetoond door Kim (2014). Sindsdien is de populariteit van CNN’s in deze discipline toegenomen (Sun en Gu, 2017).
Een aanzienlijk probleem bij tekstclassificatie is de onzekerheid over de juistheid van de voorspellingen. Hierdoor blijft menselijke controle noodzakelijk. Hoewel handmatige categorisatie van teksten niet meer vereist is, moeten de geproduceerde klassen nog wel worden nagekeken en soms aangepast. Het zou nuttig zijn om de benodigde handmatige controle te reduceren, zodat niet elke voorspelling van de tekstclassificator geverifieerd hoeft te worden. Dit kan worden bereikt door het classificatiemodel uit te rusten met een systeem dat naast elke klassevoorspelling ook een indicatie geeft van de mate van zekerheid over die voorspelling. Dit kan door de resultaten van de tekstclassificator te gebruiken voor Risico Niveau Voorspelling (RLP). RLP biedt een risiconiveau voor elke voorspelling, wat aangeeft of deze riskant (hoog risiconiveau) of veilig (laag risiconiveau) is. Deze strategie verhoogt de effectiviteit van het classificatiesysteem doordat de classificator zich bewust is van zijn eigen foutenmarge. Het aantal vereiste menselijke controles kan hierdoor worden verminderd: voorspellingen met een laag risiconiveau hoeven niet te worden gecontroleerd, terwijl alleen voorspellingen met een hoog risiconiveau menselijke validatie vereisen.
Figuur 1 toont het voorgestelde classificatieproces.
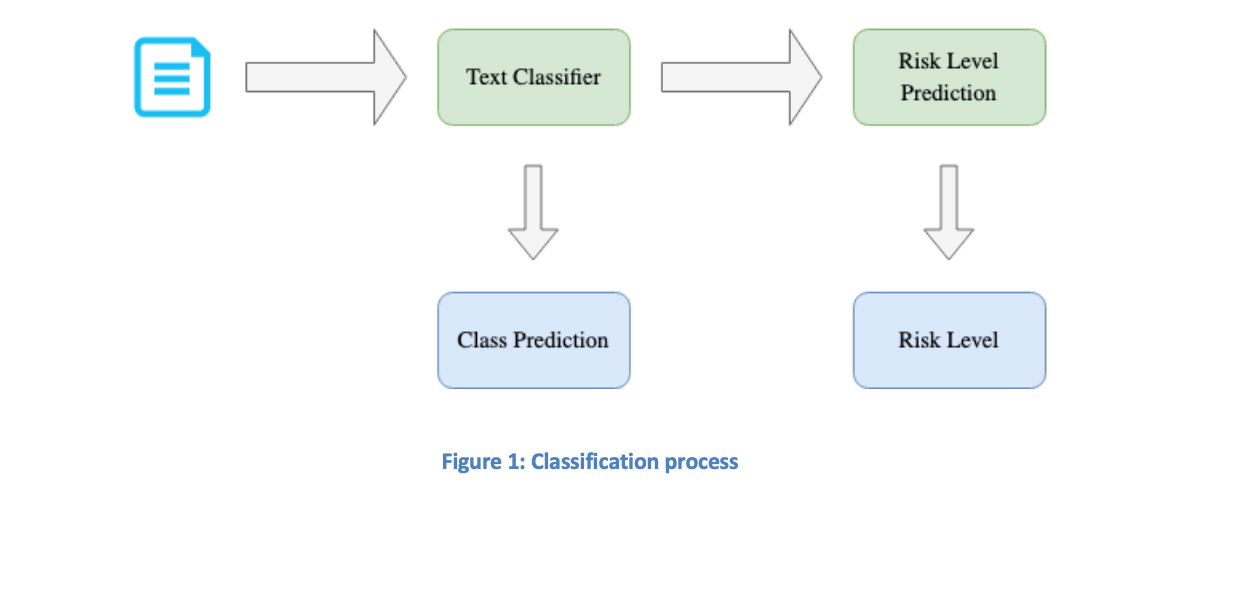
Tekstclassificatie
Tekstclassificatie speelt een steeds grotere rol in bedrijven, omdat het inzichten uit tekstuele gegevens kan extraheren en bedrijfsprocessen kan automatiseren. Het automatiseren van classificatie op basis van tekst heeft veel toepassingen waarbij handmatige taken geëlimineerd kunnen worden. Voorbeelden hiervan zijn sentimentanalyse van gebruikersrecensies, waarbij beoordelingen worden gecategoriseerd als positief, negatief of neutraal, en productclassificatie, waarbij producten automatisch worden ingedeeld op basis van hun beschrijvingen.
Er zijn diverse classificatiemethoden beschikbaar voor tekstclassificatie (Kowsari et al., 2019). In deze blog zullen we drie verschillende benaderingen voor tekstclassificatie bespreken.
Model 1: TF-IDF Logistische Regressie
Een eenvoudig maar effectief model voor tekstclassificatie is TF-IDF logistische regressie (Wang et al., 2017). Deze techniek genereert TF-IDF kenmerkvectoren uit teksten en gebruikt deze voor classificatie binnen vooraf gedefinieerde categorieën via logistische regressie. TF-IDF staat voor Term Frequency - Inverse Document Frequency en is bedoeld om de relevantie van een woord voor een specifieke tekst in de context van een gehele documentverzameling te duiden. De kenmerken worden berekend met een gewogen score op basis van het voorkomen van een woord in de specifieke tekst versus in de totale verzameling. Dit systeem benadrukt woorden met waardevolle informatie, maar negeert ook de volgorde en context waarin woorden voorkomen, wat resulteert in verlies van belangrijke semantische informatie.
De logistische regressietekstclassificator wordt getraind op deze TF-IDF featurevectoren en kan daarna worden ingezet om nieuwe teksten te classificeren op basis van hun TF-IDF gegevens.
Model 2: Convolutioneel Neural Netwerk
In tegenstelling tot TF-IDF logistische regressie zijn Convolutionele Neurale Netwerken (CNN’s) in staat om context en woordrelaties te benutten. Dit wordt bereikt door speciale representaties van woorden, bekend als woordinbeddingen.
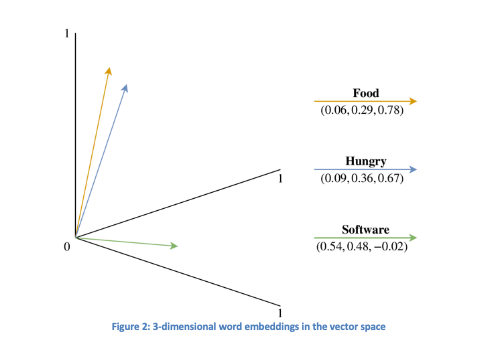
Woordinbeddingen converteren menselijke taal naar een numerieke representatie. Elke woordinbedding is een vector die de kenmerken van een bepaald woord representeert. Hoe dichter twee woordinbeddingvectoren bij elkaar liggen, hoe semantisch gerelateerde deze woorden zijn. Elke tekst in de dataset heeft een corresponderende vector. Figuur 2 geeft een eenvoudig voorbeeld van 3D-woordinbeddingen voor de woorden “eten”, “hongerig” en “software”, waarbij de eerste twee dicht bij elkaar liggen, wat hun relatie aangeeft, terwijl “software” verder weg is. Gewoonlijk hebben woordinbeddingen hogere dimensies (gewoonlijk 50, 100, 200, 300) voor een duidelijkere representatie.
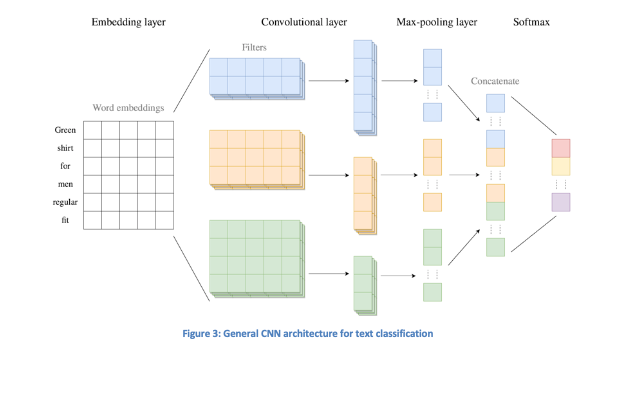
Hieronder wordt een specifieke architectuur van een CNN besproken, weergegeven in Figuur 3. De CNN bestaat uit meerdere aan elkaar verbonden lagen. De eerste laag is de inbeddingslaag, die integer gecodeerde teksten als invoer accepteert en inbeddingsgewichten voor woorden initieel toekent. Deze gewichten worden tijdens de training geoptimaliseerd door regelmatig aanpassingen door te voeren (een epoch is een volledige cyclus door het netwerk). In afbeelding 3 worden de woordinbeddingen geïllustreerd voor de woorden in de tekst “Groene shirt voor mannen met regular fit”, met woordinbeddingen van dimensie 5.
Vervolgens komt de convolutielaag, die de teksten in woordinbedingsequenties omzet en featurevectoren creëert door deze woordembeddings te analyseren met convolutiefilters, matrices gevuld met gewichten die meerdere opeenvolgende woorden tegelijkertijd onderzoeken. Deze procedure genereert kenmerkkaarten door verschillende filters te gebruiken die specifieke relaties tussen woorden detecteren. De filters kunnen variëren in hoogte, wat aangeeft hoeveel opeenvolgende woorden in elke beoordeling worden meegenomen. Bias wordt toegevoegd aan de kenmerkkaarten na de convolutie, waarna een activatiefunctie (ReLU is de meest gangbare) wordt toegepast om complexere relaties mogelijk te maken.
Na de convolutielaag volgt de poolinglaag die de kenmerkvectoren met variabele lengtes omzet in vectoren van vaste lengtes en zo irrelevante lokale informatie verwijdert.
De laatste laag van de CNN is de softmax-laag, die de kenmerkvectoren als input gebruikt en de output verwerkt via een volledig verbonden laag die niet-lineaire combinaties van eigenschappen leert. De softmax-functie converteert deze output naar waarschijnlijke waarschijnlijkheden voor elke klasse. De klasse met de hoogste waarschijnlijkheid is de uiteindelijke voorspelling.
Tijdens het trainen van de CNN worden de gewichten in de inbeddingslaag, convolutielaag en softmax-laag geoptimaliseerd met behulp van de categorische cross-entropie verliesfunctie, wat deel uitmaakt van het backpropagation-proces, essentieel voor neurale netwerken.
Model 3: Zachte Stemming
We hebben tot nu toe twee tekstclassificatoren gezien: logistische regressie en CNN. Om de prestaties van deze modellen te verbeteren, kunnen ze gecombineerd worden tot een ensemble-classificator met behulp van een zogenaamde Soft Voting (SV) classifier. Hierbij worden klassen aangeduid door een gewogen gemiddelde van de klassewaarschijnlijkheden van de LR- en CNN-classificatoren. Dit kan nuttig zijn als beide classificeerders vergelijkbare prestaties leveren, doordat ze elkaars zwakke punten compenseren. De SV-gewichten worden vastgesteld aan de hand van een validatieset van teksten die niet voor training zijn gebruikt.
Zodra de gewichten bepaald zijn, is het soft vote model klaar om de gewogen voorspellingen voor elke klasse te berekenen. De klasse met de hoogste gewogen voorspelling is vervolgens de output van de SV-textclassificator.
Voorspelling Risiconiveau
Zoals eerder vermeld, bestaat er onzekerheid bij de klassevoorspellingen van een tekstclassificator. Om deze onzekerheid te beoordelen, wordt er een methodologie gepresenteerd voor risicobeoordeling via Risk Level Prediction (RLP). Deze techniek biedt een risiconiveau per klassevoorspelling, dat inzicht geeft in de mate van ‘onzekerheid’ van de classificator betreffende die voorspelling. Alleen klassevoorspellingen met een hoog risiconiveau dienen handmatig gecontroleerd te worden.
Methodologie
Bij multi-class classificatie wordt de klasse die overeenkomt met een tekst toegewezen op basis van de hoogste voorspellingswaarschijnlijkheid van de classificator. Deze waarschijnlijkheid kan dienen als indicator voor de risico-inschatting. Hoe groter de waarschijnlijkheid, hoe zekerder de classificator is van zijn voorspelling. Om echter een nog betere risico-inschatting te maken, kunnen extra indicatoren worden ingezet.
De RLP behelst het trainen van een tweede classifier die risicofactoren als input gebruikt en voorspelt of de klassevoorspelling ‘juist’ of ‘verkeerd’ is. Deze tweedegraads classifier wordt gedegen getraind door de oorspronkelijke dataset te splitsen in twee subsets: één voor het trainen van de tekstclassificator en de andere voor de classifier van de RLP. De procedure omvat de volgende stappen:
- De tekstclassificator wordt op de gebruikelijke manier getraind op de eerste data subset.
- Met de getrainde classifier worden de klassen voorspeld voor de tweede subset, wat ons in staat stelt om de voorspellingen te vergelijken met de werkelijke klassen, resulterend in een binaire variabele (‘correct’ of ‘wrong’). Deze variabele vormt de doelstelling voor de RLP-classifier. Door risicofactoren te gebruiken als kenmerken, wordt de RLP-classifier getraind om te voorspellen of de door de tekstclassificator toegewezen klasse correct of onjuist is.
Om de RLP-classifier effectief te maken, dienen we relevante kenmerken te selecteren die het risico van een voorspelling reflecteren. Voorbeelden zijn top-k voorspelde waarschijnlijkheden, zinslengte en statistieken over de klassen.
RLP-varianten
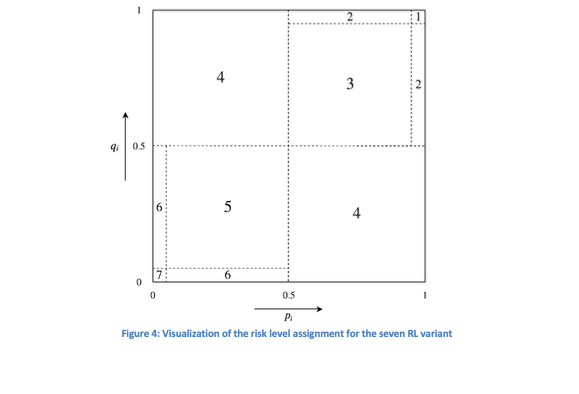
De RLP maakt gebruik van een binaire classifier die de voorspellingen als ‘juist’ of ‘verkeerd’ categoriseert, gebaseerd op een traditionele drempel. Wanneer de voorspelde waarschijnlijkheid boven 0,50 ligt, wordt de voorspelling als ‘juist’ en daaronder als ‘verkeerd’ gelabeld. Hierdoor kunnen risiconiveaus worden toegekend aan de voorspellingen van de tekstclassificator. Een risiconiveau van 1 wordt toegekend aan een beoordeling die als niet-riskant en betrouwbaar wordt beschouwd, terwijl een niveau van 2 staat voor risicovolle en onbetrouwbare voorspellingen.
De beschreven RLP-variant gebruikt één binaire classifier, maar het is ook mogelijk om twee classificeerders te gebruiken. Dit biedt de mogelijkheid om een klassevoorspelling met risiconiveau 1 toe te kennen als beide classificators ‘juist’ voorspellen (afhankelijk van de drempel van 0,50); anders wordt risiconiveau 2 toegekend.
Dit concept kan verder worden uitgewerkt naar RLP-varianten die meer dan twee risiconiveaus mogelijk maken. Als beide classificators met hoge zekerheid ‘juist’ voorspellen, kan een laag risiconiveau worden toegekend; als één met hoge দাবি ‘juist’ onderstreept en de ander met lage zekerheid volgt, kan de aanname gemaakt worden dat de voorspelling iets riskanter is. Dergelijke varianten, waarbij verschillende risiconiveaus aan voorspellingen worden toegekend door twee binaire classifiers te combineren, worden visueel weergegeven in Figuur 4.
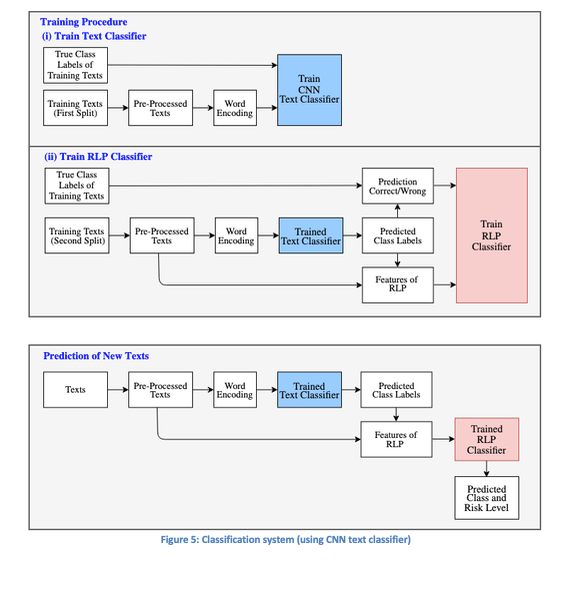
Classificatiesysteem
Figuur 5 biedt een compleet overzicht van het classifier-systeem zoals beschreven in deze blog. De CNN-textclassificator wordt gebruikt voor het maken van klassevoorspellingen. Eerst wordt de CNN-textclassificator getraind op een deel van de trainingsdata, gevolgd door het trainen van de RLP-classifier op de andere subset. Uiteindelijk kan het systeem zich toepassen op nieuwe teksten voor zowel klassevoorspellingen als het koppelen van risiconiveaus aan deze voorspellingen.
Referenties
- Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).
- Kowsari, K., Meimandi, K.J., Heidarysafa, M., Mendu, S., Barnes, L. and Brown, D. (2019). Text Classification Algorithms: A survey. Information, 10 (4), 150.
- Sun, S. and Gu, X. (2017). Word Embedding Dropout and Variable-Length Convolution Window in Convolutional Neural Network for Sentiment Classification. ICANN 2017 (2), 40–48.
- Wang, Y., Zhou, Z., Jin, S., Liu, D. and Lu, M. (2017). Comparisons and Selections of Features and Classifiers for Short Text Classification. IOP Conference Series: Materials Science and Engineering, 261.
- Wang, Zhou, Jin, Liu, Lu (2017) Comparisons and selections of features and classifiers for short text classification.
